SSTable为Sorted String Table的简称,用来存储一系列有序Kev-Value对。LevelDb中不同层级下有多个SSTable文件(.sst),下面介绍单个SSTable文件的静态结构。
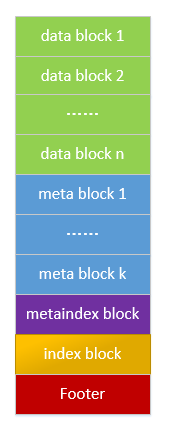
单个SSTable文件的格式如上图所示,文件由五大部分组成:Data Blocks, Meta Block, Meta Index Block, Data Index Block, Footer。
- Data Blocks: 存储一系列有序的key-value
- Meta Block:存储key-value对应的filter(默认为bloom filter)
- Meta Index Block: 指向Meta Block的索引
- Data Index BLocks: 指向Data Blocks的索引
- Footer : 指向索引的索引
下面对这几快一一讲解。
Data Block
Data Block是基于block_builder.cc生成的。存储了有序的key-value对,内部的基本结构如下:
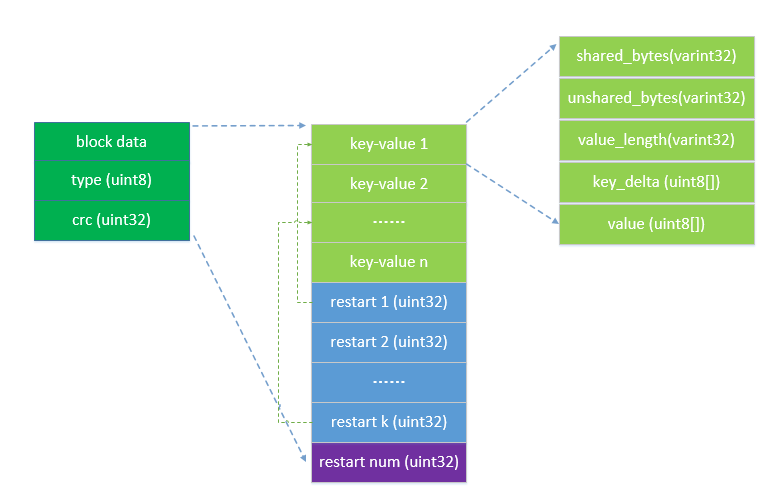
其中
-
block data为实际的key-value值
-
type目前只有0或者1。0表示block数据未压缩,1表示使用了Snappy压缩(LevelDb中的压缩以block为单位)。
-
crc 表示block data和type的crc校验值
- 除了Data Block 其他所有的的Meta Block 、Index Block等都有type和crc字段,后面讲述Meta Block及其他Block时不再表示。
- 每个block大小通过options.block_size指定的,默认为4K。实际情况中某个block有可能超过4K,原因在table_builder.cc的Add逻辑中 判断逻辑为(estimated_block_size >= options.block_size) 可能会出现Add完一个后block超出block_size的情况。
当存储一个时LevelDb采用了前缀压缩(prefix-compressed),由于LevelDb中key是按序排列的,这可以显著的减少空间占用。另外,每间隔k个keys(目前版本中k的默认值为16),LevelDb就取消使用前缀压缩,而是存储整个key(我们把存储整个key的点叫做重启点)。这样的好处是提高在block中检索key的速度。在block中随机检索一个key时,可以先对重启点进行二分查找,缩小查找范围,然后再遍历查找。如果没有重启点,在block中查找某个key的时候只能顺序遍历,因为如果要知道第i+1条记录需要知道第i条记录的key,如果要恢复第i条记录需要知道第i-1条记录的key,一直这样递归下去,才能知道key值。 另外,从数据结构上看,LevelDb还使用了varint类型来进一步对数据进行压缩,varint对整数类型进行变长编码,比如可以将一个4字节的int32值最短可以编码成1个字节表示,最长编码成5个字节,对于小整数来说,压缩效果很明显。(要了解前缀压缩、varint编码、CRC校验等基本知识可以参照phylips的”LevelDb SSTable格式详解”)
block size大小对性能的影响:
LevelDb 以block为单位进行磁盘读写操作,默认的block大小在压缩前在4096个字节左右,需要结合使用场景来调整block size的大小,如果是顺序访问或者单个key-value的值比较大可以将block size设置大些,如果是随机访问的话可以将block size设置的小一些(索引粒度变细,加快查找速度),将block size设置太小有可能导致创建SSTable文件时变慢(原因是以block为单位压缩及Flush)。并且将block设置为1KB以下或者几兆大小不会带来明显的好处。
Meta Block
Meta Block用来存储一些元信息。目前的版本中仅存储了filter信息。如果打开数据库时指定了”FilterPolicy”, 那么每个Table中都会存储一个filter block。LevelDb中默认的FilterPolicy为bloom filter。在查找某个时(DB::Get()),可以先通过FilterPolicy来判断key是否在某个SSTable中,如果不存在,则直接跳过此SSTable,避免对此SSTable进行更进一步的磁盘访问操作。 table的filter block中存储了一系列的filters。每个filter又是由一系列的key生成的,第i个filter由在sstable中文件偏移为[ibase…(i+1)base]的所有key生成的,base默认为2KB。生成filter的操作在table_builder.cc中,由TableBuilder::Flush()函数调用。当某个block超过了options.block_size时,调用TableBuilder::Flush()将此block刷新到磁盘,并调用FilterBlock::StartBlock(block_offset)函数,StartBlock函数根据此block在文件中的offset来判断是否创建新的filter。由此可见,一个filter可能会对应多个block,一个block肯定不会跨越两个filter。访问时先从data index block中得到data block在文件中的offset,然后通过offset计算出该block在哪个filter,之后就可以直接读取该filter数据。block filter文件组织格式如下:
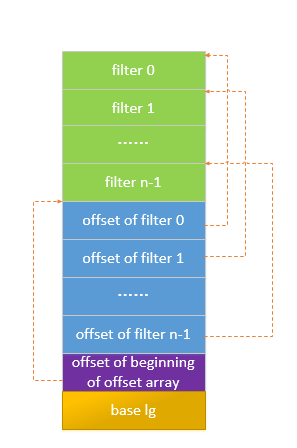
(PS: lg(base)存储的是对2取对数的值,如果base=2KB,那么lg(base) = lg(2*1024) = 11)
Meta Index Block
Data Block、Meta Index Block及Data Index Block都是由BlockBuilder类生成。即这三个block内部结构都相同(见Data Block格式详解)。不同的地方是Meta Index Block只存储了一个key-value对。而Data Index Block没有采用前缀压缩(即options.block_restart_interval=1)。Meta Index Block 存放指向Meta Block(也就是filter block)的索引,Meta Index Block 中的 key = “filter.” + options.filter_policy->Name()。Value为经过varint编码的BLockHandle。BlockHandle由offset和size组成,表示Block在文件中的偏移以及block的大小。
Data Index Block
前面介绍过,Data Index Block跟Data Block内部格式相同,只是没有采用前缀压缩。Data Index Block中存放指向Data Block的索引。对于Data Index Block来说,他的每个key-value值均指向一个对应的Data Block(通过BlockHandle表示),通过这个key-value值就可以寻址到对应的Data Block。为了减小Data Index Block占用的空间大小,LevelDb在对每个key-value对选择key时做了优化。理论上只要key值得选择满足(大于等于所对应Data Block的最大值且小于下一个Data Block的最小值)即可。 比如,假设要索引的Data BLock最大值为”the quick brown fox” 下一个Data Block的最小值为”the who”。那么,我们可以选择”the r”作为要索引的Data Block的key。而不是选择”the quick brown fox”作为key。显然,这样占用的空间会减少很多。 具体的实现在table_builder.cc中,借助bool pending_index_entry 来实现。当一个data block结束时LevelDb不会为这个data block生成索引信息,直到遇到下一个block的第一个。通过调用options.comparator->FindShortestSeparator(&block_last_key, new_block_first_key)。来得到最佳的key,然后为data block生成索引。
需要说明的是,Meta Index Block 还有Data Index Block 及后面的所有的index block指向的索引都是由BlockHandle表示的,且是经过varint编码的。结构如下:
offset: varint64
size: varint64
Footer
每个SSTable文件末尾都会有一个大小固定的footer,长度为48个字节。它包含Meta Index Block 和 Index Block的BlockHandle(即offset和size),还包含一个magic number。
metaindex_handle: char[p]; // Block handle for metaindex
index_handle: char[q]; // Block handle for index
padding: char[40-p-q]; // zeroed bytes to make fixed length
// (40==2*BlockHandle::kMaxEncodedLength)
magic: fixed64; // == 0xdb4775248b80fb57 (little-endian)
说明,一个uint64整数经过varint64编码后最大占用10个字节,一个BlockHandle包含两个uint64类型(size和offset)则一个BlockHandle最多占用20个字节,即BLockHandle::kMaxEncodedLength=20。metaindex_handle和index_handle最大占用字节为40个字节。magic number占用8个字节,是个固定数值,用于读取时校验是否跟填充时相同,不相同的话就表示此文件不是一个SSTable文件(bad magic number)。padding用于补齐为40字节。
至此,整个SSTable的静态结构就总结完成,后续会继续讲解其动态生成或读取等逻辑。
参考:
leveldb源码
SST格式详解(1)
http://www.samecity.com/blog/Article.asp?ItemID=100(LevelDb日知录之四:SSTable文件)