LevelDB中日志文件(*.log)存储了对DB的更新操作,log文件的主要作用是防止系统崩溃后数据的丢失。每次write操作,都会先写log文件,再记入内存中,这样即使系统崩溃,也可以从log文件中恢复数据。
log文件格式
log文件由一系列的block组成,每个block大小为32KB。每个block包含一个或者多个记录(record)。 记录的格式为:
checksum: uint32 // type及data[]对应的crc32值
length: uint16 // 数据长度
type: uint8 // FULL/FIRST/MIDDLE/LAST中的一种
data: uint8[length] // 实际存储的数据
说明:
-
记录实际的数据存储是从第8个字节开始的(前7个字节存储记录header信息)
- 记录永远不会从一个block的最后6个字节开始(无法存储完整的checksum/length/type)。如果一个block还剩余或者不满6个字节,则剩余部分会被填充 zero bytes(‘\0’),并且在读取的时候跳过。
- 如果当前block正好剩余7个字节,并且一个长度不为0的记录要添加进来,则会在此block的后7个字节里填充type为FIRST,length为0。此记录的data将会在随后的block中填充。
- type为FULL时,block中的记录保存了用户的所有数据;type为FIRST/MIDDLE/LAST时,用户记录被切分为不同的fragment(往往是由于record在block的边界)。FIRST代表是记录的第一个fragment, LAST表示是一个记录的最后一个fragment,MIDDLE代表是记录的中间fragments。
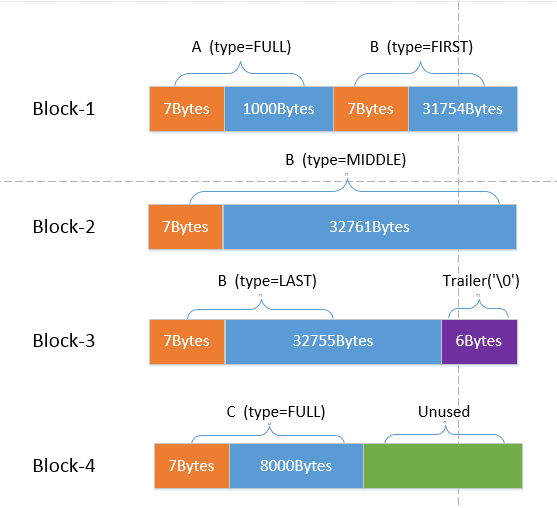
假设有如下一系列的用户记录:
A: length 1000
B: length 97270
C: length 8000
如下图所示: A记录将会在第一个block中填充为FULL类型。B记录将会被切分成3个fragment。第一个fragment占据了第一个block剩余的空间;第二个fragment占满了第二个block;第三个fragment占据了第三个block的前半部分;第三个block还会剩余6个空闲字节,将会被填充为zero type来作为尾部。C记录将会被填充费FULL类型,占据第四个block。
具体实现(log_format.h log_writer.h log_reader.h)
log_format
内容比较简单,定义了record type及block size等
Writer类
Writer类对外只暴露AddRecord()接口,即向文件中添加记录,具体实现不表,倒是实际负责文件写操作的WritableFile在Linux下的实现PosixWritableFile(util/env_posix.cc)值得一讲。 PosixWritableFile主要由3个成员函数:Append/Flush/Sync。
Append和Flush的实现如下:
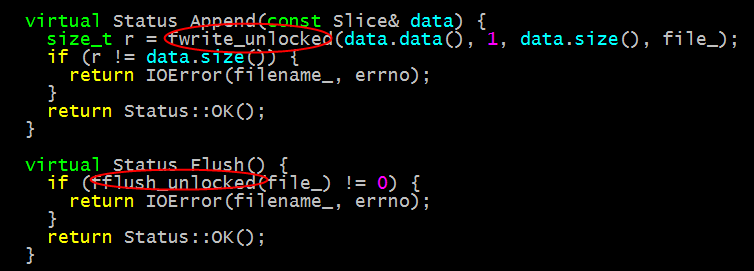 从上面的实现中可以看出,leveldb使用了不加锁的标准I/O操作fwrite_unlocked()与fflush_unlocked(), 相比使用fwrite()与fflush(),省去了加锁的开销,这会带来可观的性能提升。在设计应用时,可以把所有的I/O委托给单个线程(或者把所有的I/O委托给线程池,每个流映射到线程池中的一个线程)并结合使用不加锁I/O来提升性能。可以参考理解文件I/O-topic5了解更多缓冲I/O相关。
从上面的实现中可以看出,leveldb使用了不加锁的标准I/O操作fwrite_unlocked()与fflush_unlocked(), 相比使用fwrite()与fflush(),省去了加锁的开销,这会带来可观的性能提升。在设计应用时,可以把所有的I/O委托给单个线程(或者把所有的I/O委托给线程池,每个流映射到线程池中的一个线程)并结合使用不加锁I/O来提升性能。可以参考理解文件I/O-topic5了解更多缓冲I/O相关。
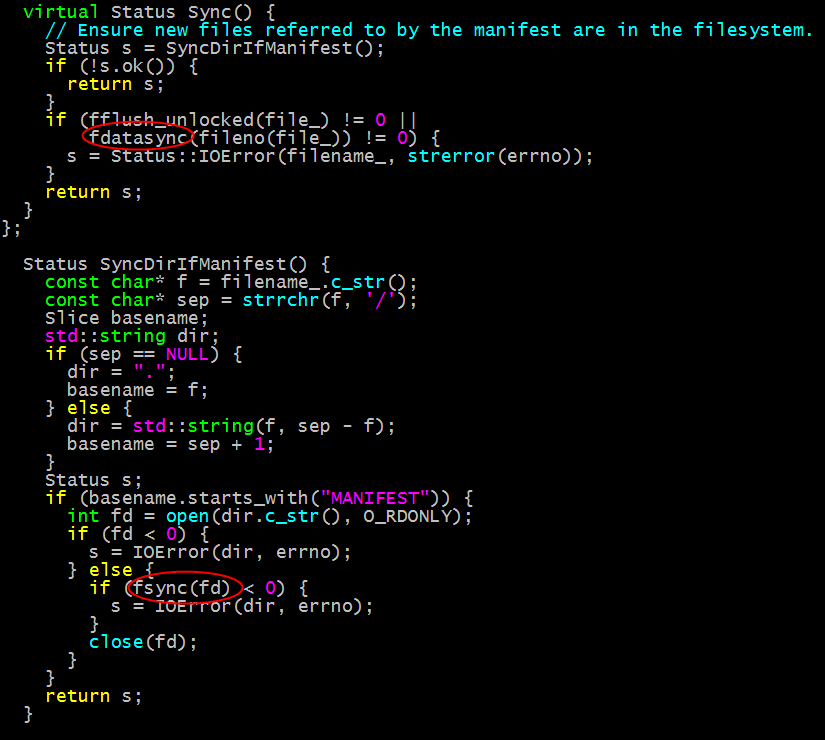
Sync的实现如下:
-
这里既有Flush又有Sync的原因是PosixWriter使用了C标准I/O库进行写文件操作,Flush操作负责将应用层缓冲数据写到到内核缓冲。Sync操作则负责将内核缓冲数据写到磁盘。
-
在刷新内核数据时使用了fdatasync()以及fsync()函数。且sync文件的同时对文件所在的目录也执行了fsync()命令(SyncDirIfManifest中),具体原因可以参考理解文件I/O-topic4
Reader类
Reader类通过ReadRecord()来读取一个记录,第一次读取时,根据initial_offset跳过log文件开始。每次读取的record都是一个完整的record(会对kFirstType/kMiddleType/kLastType进行拼接),读取过程中如果遇到BadRecord,会将此record连同record所在的整个block一起丢弃。leveldb判定为BadRecord的情形有:
-
(kHeaderSize + header中存储的记录的长度 > 当前block的剩余buffer) 且没有到文件尾(EOF)。(PS,如果到了文件尾,很有可能是写程序在写完header信息后还没来得及写data就异常退出了,这时候会返回kEof而不是kBadRecord)
-
header中存储的crc32值与实际读取出的记录的crc32值不同
其他(关于防御式编程)
最后还想说明一点,leveldb在内部模块中大量使用assert()函数,这是一个非常值得借鉴的方法,涉及到防御式编程方法的使用,像一道题识别优秀的程序员这篇文章中作者提到的,误用防御式编程会大大增加的代码复杂度及降低代码可靠性,非对外接口有不言自明的约定,使用防御式编程只会增加复杂性,在内部模块中可以通过使用assert()来替代防御式编程方法。既不增加代码复杂度,又能提高健壮性。