leveldb默认使用LRU(least recently used)缓存策略。构造LRU cache的基本数据结构主要有
LRUHandle // 底层数据结构,被索引的实体信息,包含key、value、引用次数等
HandleTable // 底层数据结构,索引LRUHandle的哈希表
LRUCache // 以LRUHandle及HandleTable为基础的LRU cache具体实现
ShardedLRUCache // 管理多个LRUCache的类(适用于多线程访问场景,减少线程争用)
LRUHanle
数据结构如下
struct LRUHandle {
void* value; // key-value结构中的value值
void (*deleter)(const Slice&, void* value); // 实体被销毁前调用的函数, 由外部传入
LRUHandle* next_hash; // HashTable中用到,用于解决hash冲突
LRUHandle* next; // HashCache中用到,用于实现LRU淘汰策略
LRUHandle* prev; // HashCache中用到,用于实现LRU淘汰策略
size_t charge; // 节点占用的内存
size_t key_length; // key的长度,用于跟key_data联合使用
uint32_t refs; // 引用计数,用于记录此节点被引用的次数
uint32_t hash; // key对应的hash值,HashTable和ShardedLRUCache都用得到
char key_data[1]; // key的起始内存地址
Slice key() const {
// For cheaper lookups, we allow a temporary Handle object
// to store a pointer to a key in "value".
if (next == this) {
return *(reinterpret_cast<Slice*>(value));
} else {
return Slice(key_data, key_length);
}
}
};
LRUHandle数据结构中有一个需要特别说明的地方就是通过key_data和key_length来获得key值: 由于key值是变长的,不能通过指定一个大小,比如char key_data[100]来存储key的值,那样会造成空间浪费或key截断。有一种方法就是 将key_data也声明成char* 用来指向一个存储key值的地址,但需要为key再单独malloc一次空间,且LRUHandle与为key malloc的空间不连续。leveldb采用了一个比较巧妙的方法,就是在为LRUHandle申请空间时多申请了(key_length-1)个字节 的空间(需要通过reinterpret_cast转换成LRUHandle指针),然后从以key_data起始内存地址开始,拷贝实际的key值到后续空间。
LRUHandle* e = reinterpret_cast<LRUHandle*>(malloc(sizeof(LRUHandle)-1 + key.size())); // 多分配key.size() - 1
memcpy(e->key_data, key.data(), key.size()); // 拷贝key值到key_data开始的内存空间中。
Slice(key_data, key_length); // 这样使用就可以获取key值。
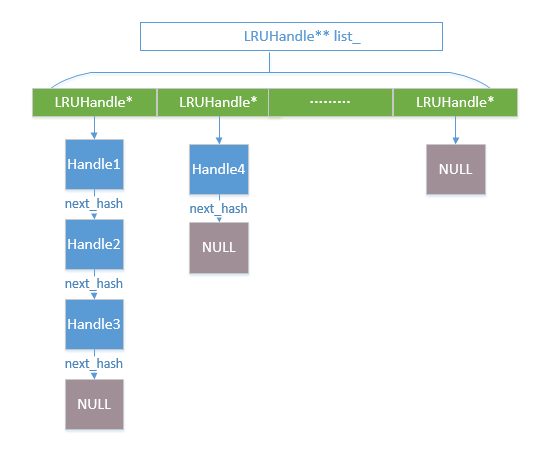
HandleTable
leveldb实现了一个简单的hashtable。原因有两个: 1. 与平台无关,不需要考虑移植。2. 在一些编译器(如gcc4.4.3)上比内置 的hashtable版本更快。 内部实现逻辑比较简单,维护了一个LRUHandle的链表,并采用拉链法来解决hash冲突。 主要变量为:
uint32_t length_; // hash链表长度
uint32_t elems_; // hash链表中当前元素个数
LRUHandle** list_; // hash链表指针
默认list_长度大小为4,当elems_达到length_时每次按照2的倍数重新申请空间。
主要接口为:
LRUHandle* Lookup(const Slice& key, uint32_t hash) // 查找key,返回节点指针
LRUHandle* Insert(LRUHandle* h) // 插入key, 如果key存在,返回NULL,否则返回key对应的
// 旧的LRUHandle指针(后续可以将其释放)
LRUHandle* Remove(const Slice& key, uint32_t hash) // 删除key,返回要删除的LRUHandle指针(后续可以将其释放)
LRUHandle** FindPointer(const Slice& key, uint32_t hash) // 内部接口,返回key在list_中的位置
leveldb在FindPointer中使用了一个小技巧,在length_为2的倍数时,可以通过 hash & (length_ -1) 来找到对应的的list_位置。 这比使用 hash%length_ 运算起来更快。
LRUHandle** FindPointer(const Slice& key, uint32_t hash) {
LRUHandle** ptr = &list_[hash & (length_ - 1)];
while (*ptr != NULL &&
((*ptr)->hash != hash || key != (*ptr)->key())) {
ptr = &(*ptr)->next_hash;
}
return ptr;
}
HandleTable的结构如下:
LRUCache
LRUCache主要成员函数如下:
size_t capacity_; // LRU Cache的总容量大小
mutable port::Mutex mutex_; // 用于保护下面三个变量状态
size_t usage_; // LRU Cache的使用量
LRUHandle lru_; // 双向链表的傀儡节点,lru.prev指向最新被访问过的实体,lru.next指向最旧的实体
HandleTable table_; // 存储实体的hash表
LRUCache使用双向链表lru_来实现LRU的功能, table_则存储LRUHandle实体。
lru_某一状态下结构图如下:
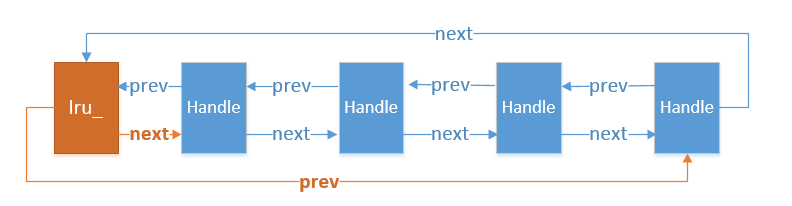 其中lru_为傀儡节点,本身不存储数据。的next指针指向最旧的Handle。prev指针指向最近被访问过的Handle。每当插入(LRUAppend)一个新的Handle时,都会插入到双向链表
的末尾,且改变lru_的prev指针指向最新插入的Handle。具体的Append和Remove操作如下:
其中lru_为傀儡节点,本身不存储数据。的next指针指向最旧的Handle。prev指针指向最近被访问过的Handle。每当插入(LRUAppend)一个新的Handle时,都会插入到双向链表
的末尾,且改变lru_的prev指针指向最新插入的Handle。具体的Append和Remove操作如下:
//添加节点到lru_双向链表中
void LRUCache::LRU_Append(LRUHandle* e) {
// Make "e" newest entry by inserting just before lru_
e->next = &lru_;
e->prev = lru_.prev;
e->prev->next = e;
e->next->prev = e;
}
//从lru_双向链表中删除节点
void LRUCache::LRU_Remove(LRUHandle* e) {
e->next->prev = e->prev;
e->prev->next = e->next;
}
可以对照上述结构图来模拟下LRU_Append及LRU_Remove操作。
LRUCache对外主要提供以下接口
// 插入key到Cache中,并返回内部生成的Handle
Cache::Handle* Insert(const Slice& key, uint32_t hash,
void* value, size_t charge,
void (*deleter)(const Slice& key, void* value));
Cache::Handle* Lookup(const Slice& key, uint32_t hash);
void Release(Cache::Handle* handle);
void Erase(const Slice& key, uint32_t hash);
void Prune();
Insert操作主要流程:
- 加锁(MutexLock l(&mutex_))
- 根据传入的信息动态生成一个新LRUHandle
- 将LRUHandle插入lru链表中(LRU_Append)
- 将LRUHandle插入table_中(table_.Insert())
- 如果table_中存在相同key(Insert函数不返回空)从lru中删除旧值(LRU_Remove)
- 如果LRUCache当前容量不足(usage_ > capacity) 则循环删除最旧数据(lru_.next)直到空间够用或lru为空
- 返回指向LRUHandle的指针
Lookup操作主要流程:
- 加锁(MutexLock l(&mutex_))
- 调用table_.Lookup看是否存在
- 如果存在(返回为e),移动对应LRUHandle在lru_中位置(LRU_Remove(e); LRU_Append(e)) 这样e即移动到了链表最后
- 返回指向LRUHandle的指针(e)
下面部分翻译自rocksdb文档:
动态分配的LRUHandle可能会有以下状态:
- 外部有引用且在hashtable中(refs > 1 && in_cache == true)
- 没有被外部引用并且在hash表中(refs == 1 && in_cache == true)
- 被外部引用了并且不在hash表中(refs >= 1 && in_cache == false)
所有新创建的LRUHandle的状态都是1. 如果对处在状态1的实体调用了LRUCache::Release,它将会进入状态2. 对实体调用LRUCache::Erase,状态会从1到3,对相同的key调用LRUCache::Insert也会使状态从1到3 对处在状态2的实体调用LRUCache::Lookup,状态会重新变为1 在析构LRUCache之前,要确保所有的实体状态都不为1。
SharedLRUCache
为了加速多线程查找速度(每次LRUCache调用都需要互斥锁)以及减少Hash冲突 ShardedLRUCache将16个LRUCache对象放到一起(shard),然后根据key的前四个字节(最多可以代表16)选择不同shard。 关键的数据结构和函数如下:
static const int kNumShardBits = 4;
static const int kNumShards = 1 << kNumShardBits; // 位操作技巧
class ShardedLRUCache : public Cache {
private:
LRUCache shard_[kNumShards];
......
static uint32_t Shard(uint32_t hash) { //根据key的前4个字节来选择不同shard
return hash >> (32 - kNumShardBits);
}
virtual Handle* Insert(const Slice& key, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value)) {
const uint32_t hash = HashSlice(key); // 选择shard
return shard_[Shard(hash)].Insert(key, hash, value, charge, deleter); //插入shard中
}
virtual Handle* Lookup(const Slice& key) {
const uint32_t hash = HashSlice(key); // 选择shard
return shard_[Shard(hash)].Lookup(key, hash); // 在shard中查找
}