在tcmalloc原理剖析中介绍了tcmalloc整体结构,下面就一些常见的疑问进行分析。
问题一:PageHeap内存归还给操作系统的时机
PageHeap负责向操作系统申请及归还内存,对应的函数为PageHeap::ReleaseAtLeastNPages(num_pages), 调用该函数归还内存时以round-robin的方式每次从不同的span list中 取出一个span,并将其所代表的内存空间归还给操作系统(此span同时加入了returned列表),直到归还page数目大于等于达num_pages或者PageHeap中没有可释放的span为止。需要注意两点:
- 1.由于ReleaseAtLeastNPages(Length num_pages)归还内存采用的是按round-robin的方式,以span维度进行回收,所以归还大小可能比num_pages大,比如,假设此次回收轮询到了free_[128],则一次会归还128个page(span length = 128)。
- ReleaseAtLeastNPages只会归还PageHeap中的span。处于CentralFreeList中的span不受影响,ThreadCache中缓存的object也不受影响。
tcmalloc主要通过“手动全量归还”及“自动增量归还”还有”特殊情况下归还“三种方式将内存归还给操作系统。
1.手动全量归还
手动全量归还指的是应用程序主动调用MallocExtension::instance()->ReleaseFreeMemory()将内存归还给操作系统,此调用传递给ReleaseAtLeastNPages中的num_pages数为static_cast
2.自动增量归还
即tcmalloc定期增量的归还部分内存给操作系统。归还时机取决于PageHeap的scavenge_counter_;每次Span返还给PageHeap时(可能是从CentralFreeList返还,也可能是大内存分配直接返还,或者是大Span切分时返还,总之是调用Delete(Span)时),PageHeap的scavenge_counter_都会减去span->length。当scavenge_counter_降为0时,通过调用ReleaseAtLeastNPages(1)回收1个Span。 scavenge_counter_的值计算细节如下:
void PageHeap::IncrementalScavenge(Length n) {
scavenge_counter_ -= n;
if (scavenge_counter_ >= 0) return;
const double rate = FLAGS_tcmalloc_release_rate;
if (rate <= 1e-6) {
scavenge_counter_ = kDefaultReleaseDelay;
return;
}
Length released_pages = ReleaseAtLeastNPages(1);
if (released_pages == 0) {
scavenge_counter_ = kDefaultReleaseDelay;
} else {
const double mult = 1000.0 / rate;
double wait = mult * static_cast<double>(released_pages);
if (wait > kMaxReleaseDelay) {
wait = kMaxReleaseDelay;
}
scavenge_counter_ = static_cast<int64_t>(wait);
}
}
通过上面公式可以得到:
- FLAGS_tcmalloc_release_rate可以控制tcmalloc增量归还速度, 如果FLAGS_tcmalloc_release_rate = 0.0,那么tcmalloc不会主动增量归还内存
- 一般情况下,回收速度的计算公式为:min(kMaxReleaseDelay, (1000.0 / FLAGS_tcmalloc_release_rate) * released_pages)
- 如果本次通过ReleaseAtLeastNPages(1)调用发现没有可归还的Span,那么下次归还时机为2GB大小的Span归还给PageHeap后(scavenge_counter_ = kDefaultReleaseDelay)
- 如果FLAGS_tcmalloc_release_rate = 1.0, 且上次回收了1页大小,则下次回收时间是大约8M大小(1000个page)的Span归还到PageHeap后
- 如果想要加快tcmalloc归还内存的速度,将FLAGS_tcmalloc_release_rate设置的大些即可,tcmalloc官方推荐的值为[1.0, 10.0]
3.特殊情况下归还
特殊情况下归还包括:
- tcmalloc占用的内存达到了FLAGS_tcmalloc_heap_limit_mb限制,超过此阈值后,tcmalloc会释放超出的部分。
- PageHeap中碎片过多(即free list中的Span大量分散,没法满足申请需求), 这时候tcmalloc会将normal中的所有Span释放到returned,此过程Span会最大程度上进行合并。
问题二: ThreadCache内存回收时机
ThreadCache不会直接将内存归还给PageHeap,而是将多余内存归还给CentralFreeList;当ThreadCache归还内存时,CentralFreeList会判断待归还的内存对应的Span中是否所有的object都已经归还,如果均已归还,CentralFreeList会将此Span整体归还给PageHeap。 那么ThreadCache何时将内存归还给CentralFreelist呢?主要分两种情况:一种是某个size class的free list长度超过限额,另一种是某个thread cache的总容量超过限额;下面展开来看下。
free list长度超过限额
tcmalloc为ThreadCache中的每个size class的free list都设置了独立的max_length,代表当前free list允许的最大长度,当free list当前的大小超过max_length后,ThreadCache会回收min(max_length, num_objects_to_move)个objects到CentralFreeList。
PS: ThreadCache中size class的free list大小非常重要,如果free list太小,需要经常访问CentralFreeList影响性能;如果free list太大,又会造成空间浪费。并且由于线程还存在非对称性的alloc/free行为(比如生产者与消费者线程;消费者线程只负责free,基本上不需要有free list),所以设置free list为合适的大小比较棘手。为了更合理的设置free list大小,tcmalloc采取了“慢启动”算法:刚开始max_length设置为1,随着free list更频繁的使用,其最大长度也会跟着增长(细节略)。
thread cache的容量超过限额
tcmalloc为每个ThreadCache设置了max_size,它代表一个线程缓存中所有free list占用空间的总大小(初始的的大小为64K),当一个ThreadCache中总的free list大小超过max_size之后,tcmalloc就会遍历此ThreadCache中所有空闲列表,将空闲列表中的一些对象回收到CentralFreeList(回收的大小根据每个free list的最低水位标记确定,每次回收最低水位的1/2)。在回收完之后,tcmalloc会检查是否还有还有可用配额(所有ThreadCache的总配额不能超过TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES(默认为32M)。),如果有,则增加此ThreadCache的max_size值,如果没有,则通过轮询的方式向其他线程”偷取”部分配额(每次偷取或增加64K,具体细节见ThreadCache::IncreaseCacheLimitLocked)。通过这种方式,对缓存需求大的线程会得到更大的配额。
PS:对于使用多个线程的应用程序,TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES的默认值可能不够,如果怀疑应用程序在多线程环境下由于tcmalloc中的锁争用而引发性能问题,可以尝试增加此值;方法有两种,一种是通过环境变量设置,一种是通过MallocExtension::instance()->SetNumericProperty(“tcmalloc.max_total_thread_cache_bytes”, bytes)设置。
问题三: double-free及invalid-free情况下系统有何表现
先说结论:系统会出现未定义的行为(某一时间crash掉?或数据出现混乱?其他诡异的错误?等等) 为了方便探讨问题,这里只讨论“小内存”分配情况。对于小内存分配,free(void* ptr)的大概流程是:
先将ptr转化为PageID,再根据PageID找出对应的size class; 最后将ptr挂接到size class对应的free_list的头部。
下面以结构图的方式说明了free_list的组织:
假设某个thread cache其中的一个free list如下:
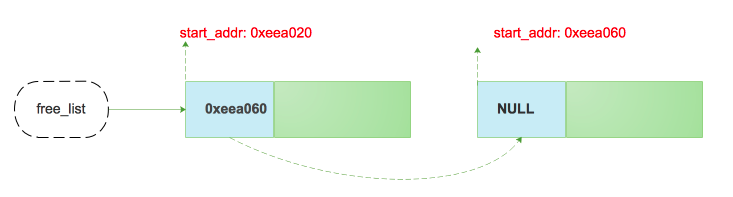 某一时刻将ptr对应的内存空间free后(假设ptr指向的地址为:0xeea020),对应的free list变为如下形式:
某一时刻将ptr对应的内存空间free后(假设ptr指向的地址为:0xeea020),对应的free list变为如下形式:
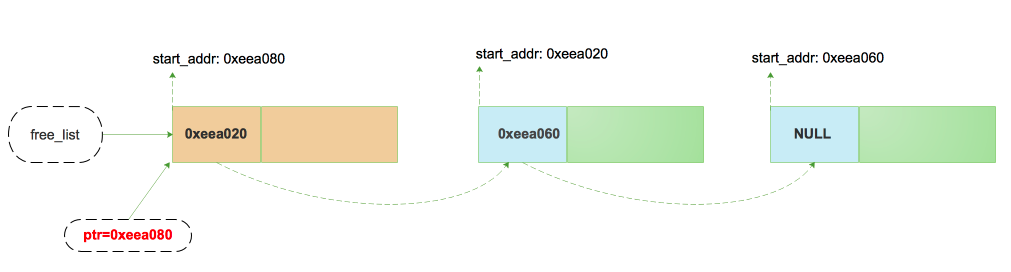
下面分别看下double-free或者invalid-free后系统的表现。
double-free
下面是一个double-free的例子
void *p0, *p1, *p2, *p3;
p0 = malloc(8);
free(p0);
free(p0);
p1 = malloc(8);
p2 = malloc(8);
p3 = malloc(8);
cout << "p0=" << p0 << std::endl;
cout << "p1=" << p1 << std::endl;
cout << "p2=" << p2 << std::endl;
cout << "p3=" << p3 << std::endl;
对代码编译执行后得到的输出为:
p0=0xee6020
p1=0xee6020
p2=0xee6020
p3=0xee6020
以上的例子中,p0指向的内存地址被释放两次,程序可以正常执行,但是后面紧跟的三次内存申请均返回同一个地址;原因在于double-free之后,free-list的头指针循环指向了自己,造成了自循环。实际上,以后无限次的申请都会指向同一个内存区域,直到应用将此内存区域写入数据并覆盖损坏循环链接的链接指针。如果同一内存区域在不同的thread中释放,情况可能会更复杂,下面是区域A在不同线程中double-free后tcmalloc内部的组织。
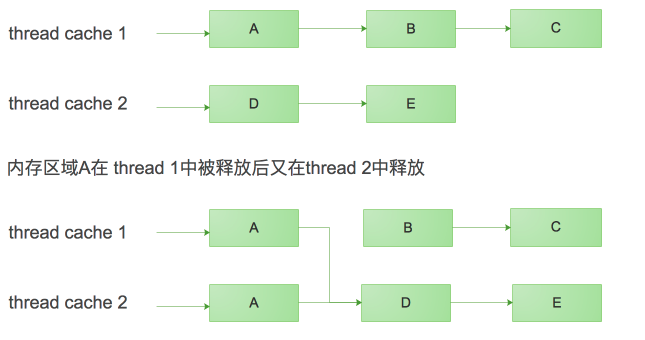 我们看到,假设区域A在不同线程中被释放两次,会导致线程1与线程2共享free-list,并且导致线程1的区域B和C泄漏。
我们看到,假设区域A在不同线程中被释放两次,会导致线程1与线程2共享free-list,并且导致线程1的区域B和C泄漏。
invalid-free
下面是一个invalid-free的例子
void *p1, *p2;
p1 = malloc(8);
free((char*)p1 + 2);
p2 = malloc(8);
cout << "p1=" << p1 << std::endl;
cout << "p2=" << p2 << std::endl;
对代码编译执行后得到的输出为:
p1=0xee6020
p2=0xee6022
上面的例子中,传递给free()函数的地址不是0xee6020,而是它之后的两个字节,即0xee6022。这时候tcmalloc不会崩溃或返回失败,相反,它会将无效的空闲指针推送到thread cache的free list中,并在下一次内存请求时将其弹出,因此p2得到的地址是没有正确对齐的无效地址,且超过了它的边界2个字节。
从上述的double-free及invalid-free的行为看,系统很有可能在当时表现正常,而运行到一段时间后crash在不相关的地方。如果出现这种情况,应该去掉tcmalloc,使用系统默认的malloc()及free()函数,系统默认的函数在double-free及invalid-free后会立即crash。另外,可以使用Address Sanitizer工具来识别double-free、invalid-free等case。具体的使用方法参见段错误调试几个tips
问题四:new()及malloc()内存分配的差别
从纯内存分配角度,没有任何差别,都是按相同的逻辑从ThreadCache或者PageHeap进行申请。主要的差别在语法上:
- 调用new()后会自动调用构造函数,delete()会自动调用析构函数,而malloc()及free()不会,所以调用malloc()一定要初始化数据,否则内存区域将会填充不确定的值,或者用calloc()替代,calloc()会把申请的内存区域初始化为0)。
- 使用new()在分配失败时可以回调指定函数(std_new_handler),malloc()不可以
- 是否可以抛出异常等其他语法差别
问题五:如何将STL默认的内存分配器改为tcmalloc
只需要链接tcmalloc,其它什么都不需要做!
为了提高内存分配的速度,STL在默认情况下申请内存时不会直接调用new()和delete(),而是维护了一个内存池,对于已经销毁的对象,STL会将其缓存到内存池中,以供下次使用。 为了禁用STL的内存池,tcmalloc在源代码中定义了如下两个环境变量:
setenv("GLIBCPP_FORCE_NEW", "1", false /* no overwrite*/);
setenv("GLIBCXX_FORCE_NEW", "1", false /* no overwrite*/);
这两个环境变量为gcc3.2.2之后定义的,会强制STL默认分配器调用new()及delete()来进行分配或者释放操作,而tcmalloc又重新定义了new()及delete()的实现,所以STL默认的内存分配器就变成了tcmalloc。 使用tcmalloc作为默认分配器会比STL内存池方式更加的快速(尤其是小内存的分配)。
参考:
2. Post-Mortem Heap Analysis: TCMalloc