本文主要总结并发编程中涉及到CPU和内存相关的基础知识,包括Amdahl‘s raw、Cache coherency、Memory fence、false-sharing等。
Amdahl‘s raw(阿姆达尔法则)
Amdahl定律的公式为: S = 1 / ( 1 - p + p / n) 其中:
- n:处理器的个数
- p:程序可并行执行的比率
- S:工作加速比,定义为由一个处理器来完成一项工作的时间与采用n个处理器并发完成该工作的时间之比
证明:假设一个处理器完成整个程序需要1个单位的时间,p是整个程序中可并行执行的时间,n个处理器并发执行程序中的并行部分需要执行时间为:p / n, 应用中串行部分执行时间为:1 - p;得出并行化后的执行时间为:p / n + 1 - p;按照Amdahl定律给出的加速比定义,得到 s = 1 /(1 - p + p/n)
理解:对于给定一个问题及具有10台处理器的机器,由Amdahl定律可知,即使其中90%的可以并行执行,相比于一台处理器也只能获得5倍的加速比,而不是10倍。也就是说,串行执行的10%使得机器的利用率降低了一半。所以在多处理编程中,要尽量使程序可并行化,比如降低锁的粒度或者不使用锁。
CPU缓存一致性(Cache Coherency)
理解CPU的缓存机制及缓存一致性的原理,是掌握并发编程中至关重要的一环,本文不打算再详细介绍相关知识,因为这篇文章Cache coherency primer (对应的翻译版本:缓存一致性入门 )已经讲得明白了。下面只列出几个重要点。
CPU多级Cache
目前常见的处理器有三级Cache,这些Cache存储的层次结构示意图如下(图片来自这里 ):
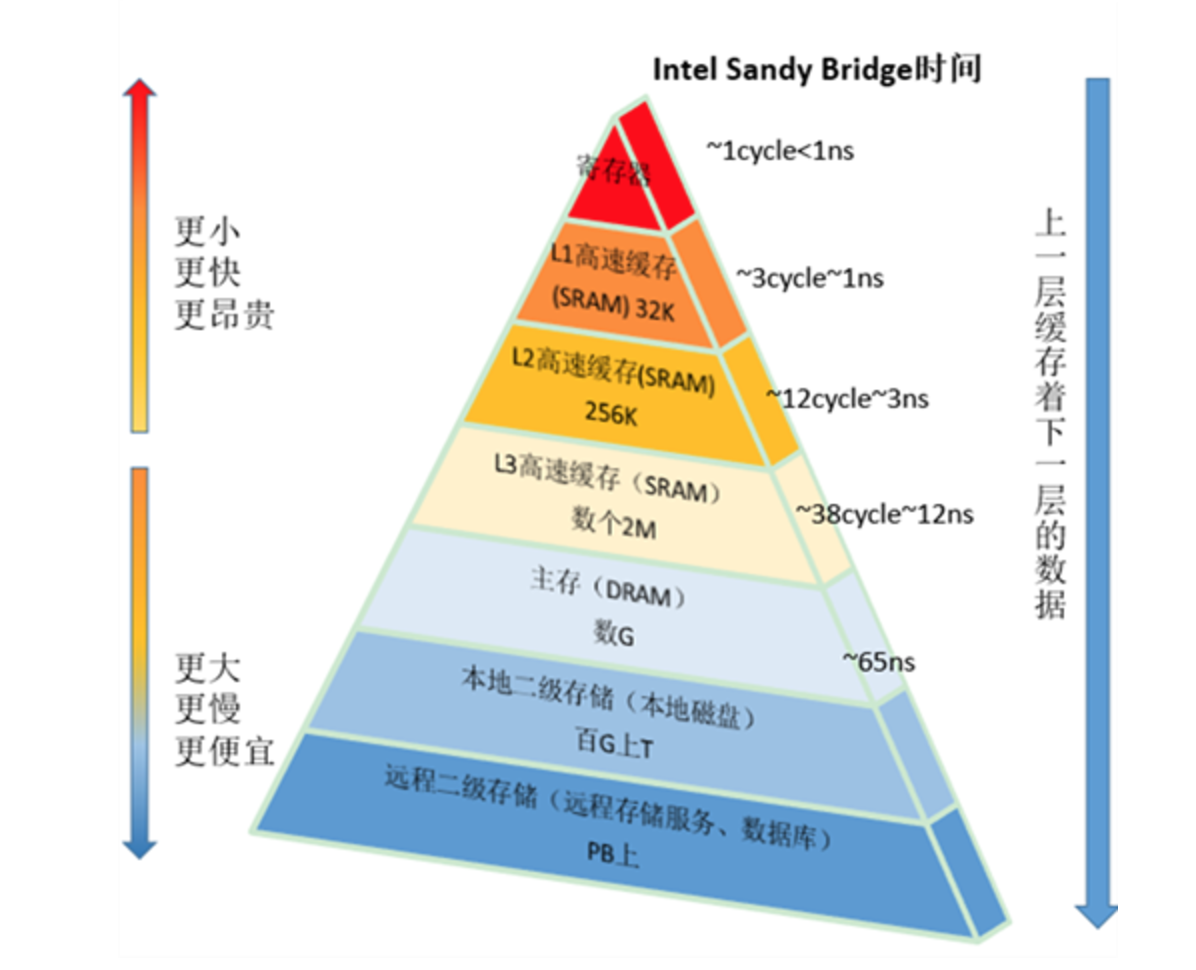 其中,L1 Cache 和L2 Cache为每个核心独有的,L3 Cache则是所有核心共享的,以4核CPU为例,对应的各级Cache大致结构图如下:
其中,L1 Cache 和L2 Cache为每个核心独有的,L3 Cache则是所有核心共享的,以4核CPU为例,对应的各级Cache大致结构图如下:
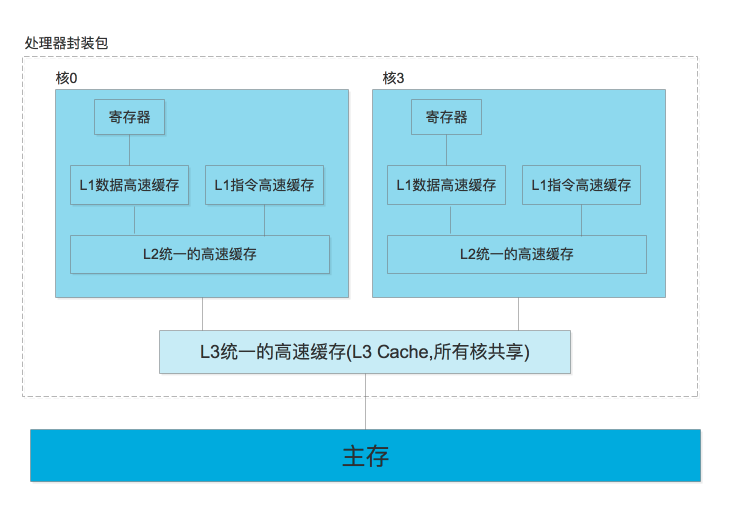
- 只所以每个CPU有独有的L1 Cache及L2 Cache,是基于性能的考虑,它可以避免多个核排队争用同一个Cache(当然,这也是让CPU变复杂的根源,它引入的CPU的一致性问题)。
- CPU的读/写单元不能直接访问内存,CPU只能和L1 Cache通讯。同样L1 Cache也不能和内存通讯,它和L2 Cache通讯,依次类推,只有L3 Cache才能和内存通讯。
- 以Intel E5-2620为例,它的L1数据高速缓存和指令高速缓存的大小为32K。L2 cache的大小为256K。L3 cache的大小为15M。
Cacheline
“段(cacheline)”是CPU Cache与内存同步的最小单位,目前常见cacheline大小为64个字节。CPU cache之所以以cacheline为单位,是基于访问局部性原理,即如果当前需要某个地址的数据,那么后续我们很可能会访问它的临近地址。我们可以提前将其加载进Cache,下次指令就可以直接使用。以Gallery of Processor Cache Effects 中举的例子来说(中文版在这里):
int[] arr = new int[64 * 1024 *1024];
// Loop1
for (int i = 0; i < arr.length; i++) arr[i] *= 3;
// Loop2
for (int i = 0; i < arr.length(); i += 16) arr[i] *=3;
第一个循环将数组的每个值乘3,第二个循环将每16个值乘3,第二个循环只做了第一个约6%的工作,但在现代机器上,两者几乎运行相同时间(在作者的机器上分别为80毫秒和78毫秒)。主要原因就是CPU以64字节为单位的块(cacheline大小)来操作内存,当读一个特定的内存地址,整个缓存行将从主存换入缓存,下一次读取相邻地址无需再从内存读取。由于16个整型数占用64字节(一个cacheline),for循环步长在1到16之间必定接触到相同数目的cacheline:即数组中所有的cacheline,即这两个循环访问内存的次数实际上是相等的,所以运行时间也相差不大。
Cache写操作及一致性
相对于读操作,写操作是让CPU变得“复杂”的最主要原因。在回写模式中,写操作只会修改本级缓存中的数据,并把相应的缓存段标记为”脏”段。”脏”段会在一定时机触发回写,即把脏段内容写到下一级缓存或者内存中。在多核CPU中,这会导致一个问题:每个核都有自己的缓存,如果某个CPU缓存段的内容被修改了,其他的CPU如何才能达到最新的数据呢?答案是:CPU的缓存一致性协议。常见缓存一致性协议为“窥探协议 + MESI协议”。窥探协议指的是:所有内存传输都发生在一条共享的总线上,与内存操作有关的所有必要的事务(读、写等)都会出现在总线上,而所有的处理器都能够看到这条总线;缓存不仅仅在做内存传输的时候才和总线打交道,而是不停地窥探总线发生的数据交换,当一个缓存代表它所属的处理器去写内存时,它会发送“独占内存权”请求给总线,这产生如下效果:
- 让其他处理器都能够得到通知,让他们将拥有的统一缓存段的拷贝失效, 以此来是自己的缓存保持同步。只要某个处理器写内存,其他处理器马上就知道这块内存在他们自己的缓存中对应的cacheline已经失效。
- 获得独占权的处理器开始修改数据,并且此时,这个处理器知道,这个缓存段只有一份拷贝,在我自己的缓存里,所以不会有任何冲突。
- 如果有其他处理器想读取这个缓存段,发现缓存数据已经失效,会向总线发送读失效消息,拥有最新缓存段的处理器会触发回写,需要读的处理器就可以读到最新的数据。
需要注意的是,缓存不会每次在收到总线事件后,都能够在当前指令周期迅速做出响应:
- 缓存不会及时响应总线事件。如果总线上发来一条消息,要使某个缓存段失效,但是如果此时缓存正在处理其他事情(比如和CPU传输数据),那么这个消息可能无法在当前指令周期中得到处理,而会进入“失效队列(invalidation queue)”,等待被处理。
- 写操作尤其特殊,因为它分为两阶段操作:在写之前我们先要得到缓存段的独占权。如果我们当前没有独占权,我们先要和其他处理器协商,这也需要一些时间。同理,在这种场景下让处理器闲着无所事事是一种资源浪费。实际上,写操作首先发起获得独占权的请求,然后就进入所谓的由“写缓冲(store buffer)”组成的队列。写操作在队列中等待,直到缓存准备好处理它”了。同时,CPU可能会根据实际情况做乱序执行(Out-of-Order excution),执行下一个指令。
Memory fence及内存可见性
前面讲到的的“invalidataion queue”及”store buffer”特性意味着,默认情况下,读操作有可能会读到过时的数据(如果对应的失效请求还invalidation queue中没有执行),写操作真正完成的时间有可能比他们在代码中的位置晚(基于性能考虑)。 加上程序编译时编译器的指令重排,这就引出了并行编程领域的执行顺序性及内存可见性问题,即一个线程修改数据对象后,另一个线程在使用时是否能够看到该数据的最新状态。举个例子说明:
// 线程1
obj.init(); // 初始化obj对象,只有初始化后才可以使用
is_inited = true;
// 线程2
if (is_inited) {
obj.do_somthing(); // 使用obj对象做些事情
}
在上面的例子中,线程2在is_inited为true时才会返回obj变量。按照线程1的逻辑,当is_inited为true时,obj应该已经初始化好了,但是
- 编译器”指令重排”或者在多核系统中”CPU内存可见性”问题都可能导致在is_inited=true时,obj还没有初始化,进而引发问题。
- 即使没有重排,线程1中的is_inited和obj有可能(不在同一个cacheline中)会独立的同步到线程2核心所在的cache中,线程2有可能看到is_inited=true时还没有看到已经初始化的obj(还在写缓冲队列中)。
如何解决呢? 主要有两种方法: memory fence或mutex。
memory fence可以让用户声明访存指令的顺序及可见性的关系,c++11中提供atomic操作,并有如下的memory order
- memory_order_relaxed: 没有fencing作用(用于原子性计数,没有上下文约束时可以使用此order)
- memory_order_consume: 现在基本上编译器都将memory_order_consume等同于memory_order_acquire
- memory_order_acquire: 内存读屏障(acquire=获取,得到),相当于清空CPU核心“失效队列(invalidation queue)“,使核心能够获取最新值,且后面访存指令不能重排到此条指令之前
- memory_order_release: 内存写屏障(release=发布,存储),相当于清空CPU核心写缓冲(store buffer),请求前面写操作指令不能排到此条指令之后。当此条指令的结果对其他线程可见后,之前的所有指令都可见
- memory_order_acq_rel: acquire + release语意
- memory_order_seq_cst: 默认值,多线程跟单线程一样用,指令之间完全有序。但是是非耗性能。
用memeory fence来解决上面的问题,示例如下:
// 线程1
obj.init(); // 初始化obj对象,只有初始化后才可以使用
is_inited.store(true, std::memory_order_release);
// 线程2
if (is_inited.load(std::memory_order_acquire)) {
obj.do_somthing(); // 使用obj对象做些事情
}
上面使用memory fence的方式虽然可以解决问题,但是很容易出错,如果怕写错,并且对性能没有非常苛刻的要求,直接使用互斥(mutex)就可以解决:mutex可以保证原子访问及内存可见性, 一旦线程修改数据对象后,其他线程在修改行为发生后能够马上看到此对象的最新状态:
// 线程1
lock(mutex)
obj.init(); // 初始化obj对象,只有初始化后才可以使用
is_inited.store(true, std::memory_order_release);
unlock(mutex)
// 线程2
lock(mutex)
if (is_inited.load(std::memory_order_acquire)) {
obj.do_somthing(); // 使用obj对象做些事情
}
unlock(mutex)
false-sharing(缓存行的伪共享)
前面讲过,每个CPU核心都有独立的Cache,并且通过CPU缓存一致性算法(ache Coherency)进行Cache之间数据的同步。这可能引发两种性能问题:
- 当某个变量需要在CPU核心中共享时,一个CPU核心改变自己Cache中的值,会通过CPU缓存一致性算法同步给其他CPU核心。其他CPU核心其对应的内存位置将不可用,需要重新同步,从而引发false-sharing问题。以全局计数器为例,如果所有线程都频繁修改一个全局变量,不同的核心就需要不停地同步同一个cacheline,导致性能变差。
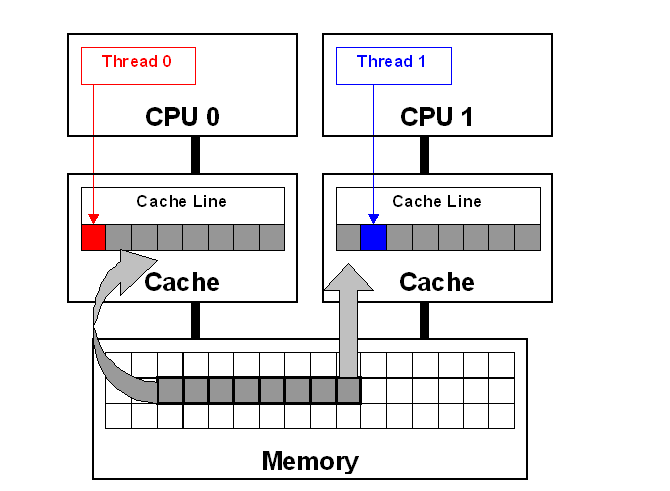
- 即使某个共享变量不会被频繁修改,但是此变量与另一个被多线程频繁修改的变量在一个cacheline中,也会引发false-sharing问题。下图是SMP框架上的false-sharing直观的举例(更细节的部分可以参考此文)
解决方法:
- 尽量减少全局变量的共享,在一些写多读少的场景下,可以将写操作拆分到每个独立的thread local变量中,在需要读的时候再将其合并,以减少cacheline的同步。
- 可以让结构体或者变量按照cacheline对齐(通过 cat /proc/cpuinfo 中的cache_alignment字段得到cacheline大小), 防止多变量在同一个cacheline中。以gcc为例,可以这样设置:
int32_t __attribute__((aligned(64))) global_var; // 变量对齐
class A {
int a1;
short a2;
} __attribute__((aligned(64))); // 类对齐
毕。