本文主要的目的是总结Linux下多线程服务器常用Reactor模式。PS:述而不作,里面很大部分知识都是总结的陈硕 (muduo网络库作者,《Linux多线程服务端编程》作者)论述,感谢陈硕前辈。
Reactor模式介绍
Linux环境下高性能网络程序中,大都使用Reactor模式,比如libevent、libev、ACE,POE(Perl)、Twisted(Python)等。那什么是Reactor模式呢?
Reactor模式本质上指的是使用”IO多路复用(IO multiplexing) + 非阻塞IO(non-blocking IO)”的模式。所谓“IO多路复用”,指的就是select/poll/epoll这一系列的多路选择器。它支持线程同时在多个文件描述符上阻塞,并在其中某个文件描述符可读写时收到通知。 IO复用其实复用的不是IO连接,而是复用线程,让一个thread of control能够处理多个连接。
所谓”非阻塞IO“核心思想是指避免阻塞在read()或者write()或者其他的IO系统调用上,这样可以最大限度的服用thread-of-control,让一个线程能服务于多个socket连接。在Reactor模式中,IO线程只能阻塞在IO multiplexing函数。
Reactor模式中非阻塞IO至关重要,有几个问题需要搞清楚,
1. 非阻塞IO和阻塞IO的区别是什么?
以发送100K字节为例,如果发送缓冲区满或不到100K,如果将IO设置成阻塞IO,它则会一直阻塞,直到100K数据全都发送成功再返回。如果将IO设置成非阻塞IO,缓冲区满时会直接返回EAGAIN或EWOULDBLOCK;缓冲区不够时直接返回复制到缓冲区的字节数,总之它不会阻塞在调用上。
2. 使用非阻塞IO时,网络库为什么必须为每个tcp连接配置input buffer及 output buffer?
考虑一个场景:程序想通过TCP连接发送100K的字节,但是在write()调用中,操作系统只接受了80K字节(受TCP advertised window控制),剩下20K字节不知道会等多久才能发送成功(取决于对方什么时候接收数据,然后滑动TCP窗口)。程序应该尽快交出控制权,返回event loop。在这种情况下,剩余的20K字节数据怎么办? 对应用程序而言,他只管生成数据,它不应该关心到底数据是一次性发送还是分几次发送,这些应该由网络库来操作,程序只需TcpConnection::send()就可以了,网络库会负责到底。网络库应该保存这剩余的20k字节数据,把它保存在Tcp connection的output buffer里,然后注册POLLOUT事件,一旦socket变得可写就立刻发送数据。当然,这第二次write()也不一定能够完全写入20K字节,如果还有剩余,网络库应该继续关注POLLOUT事件;如果写完了20K字节,网络库应该停止关注POLLOUT,以免造成busy loop。 如果程序又写入了50K字节,这时候output buffer里还有待发送的20K数据,那么网络库不应该直接调用write(),而应该把这50K数据append在20K数据之后,等socket变得可写的时候再一并写入。 如果output buffer里还有待发送的数据,而程序又想关闭连接(对于程序而言,调用TcpConnection::send()之后他就认为数据迟早会发出去),那么这时候网络库不能立刻关闭连接,而要等待数据发送完毕。
综上,要让程序在write操作上不阻塞,网络库必须要为每个tcp connection配置output buffer
TCP是一个无边界的字节流协议,接收方必须要处理”收到的数据尚不构成一条完整消息”和”一次收到两条消息数据”等情况。一个常见的场景是,发送方send了两条10K字节的消息(共20K),接收方收到数据的情况可能是
- 一次性收到20K数据
- 分两次收到,第一次收到5K,第二次15k
- 分两次收到,第一次收到15K,第二次收到5K
- 分两次收到,第一次10K,第二次10K
- 分三次收到,第一次6K,第二次8K,第三次6K
- 任何其他可能
那么网络库必然要应对数据不完整的情况,把收到的数据先放到input buffer里,等构成一条完整消息再通知程序的业务逻辑(这通常是codec的职责)。所以在tcp网络编程中,网络库必须要给每个tcp connection配置input buffer。
3. Reactor模式中非阻塞IO的典型错误使用方式
公司内部某个使用很广泛但是很老的网络库中,虽然也使用了“IO多路复用”技术,并且将IO设置成了非阻塞,但是却错用了非阻塞IO,以发送数据为例,下面是公司某网络库的代码实现(伪代码)
// 假设:要发送的数据存储在char* buf中,数据大小为total_size
total_written_count = 0
while(1) {
written_count = send(socket, buff + total_written_count, total_size - total_written_count, MSG_DONTWAIT); // 将socket设置为非阻塞,有多少写多少
if (written_count < 0 && errno == EWOULDBLOCK) { // 资源暂时不可用,继续
continue;
} else if (written_count < 0) { // 其它错误
// 报错,退出循环
}
total_written_count += written_count;
if (total_writeten_count == size) {
// 所有发送完成,返回
}
}
上面这种使用非阻塞IO的方式,在本质上来说与阻塞式IO并没有区别,因为最终还是需要将所有数据发送完毕之后再返回。当接收方因为负载过高等原因出现接受速度变慢时,这种方式可能会阻塞掉整个thread of control。 这是比较典型的错误使用非阻塞IO的方法,实际情况中应当避免。
下面开始介绍下常见的几种Reactor模式:
模式一:基本的Reactor模式(单线程Reactor)
单线程Reactor的程序结构如下:
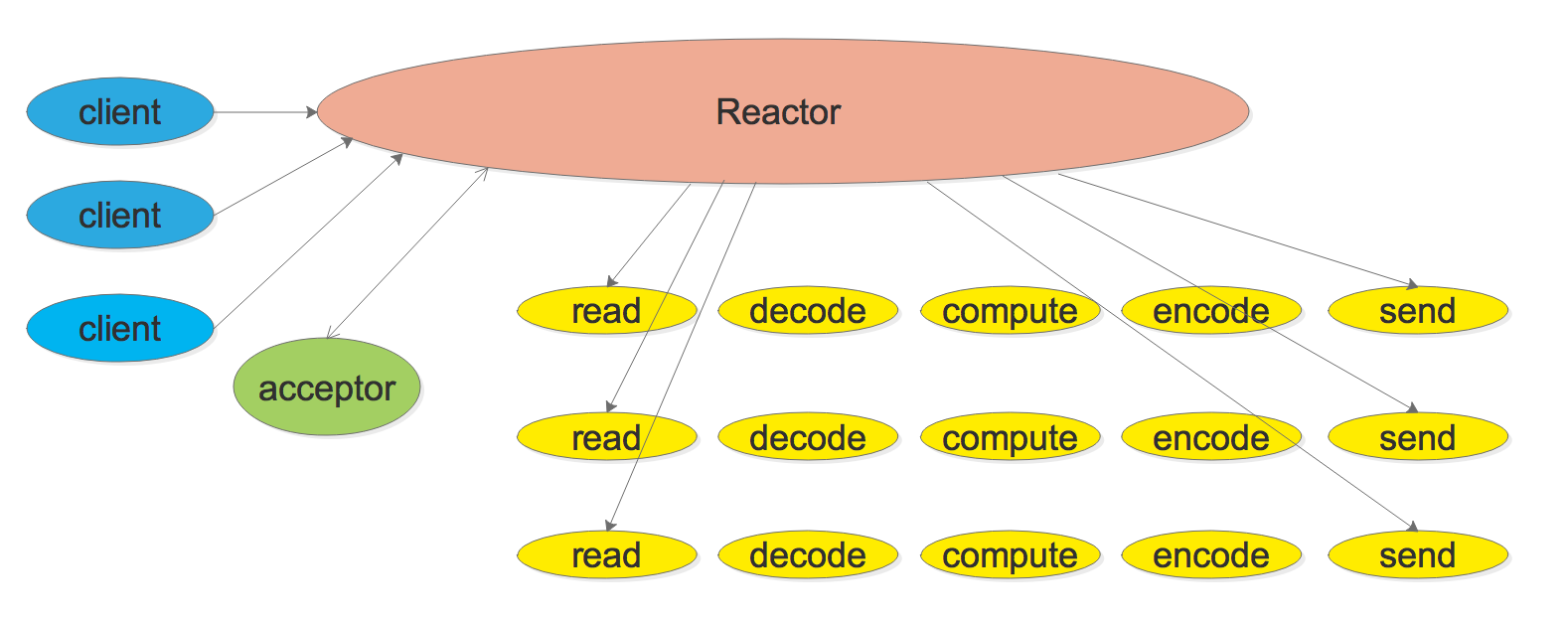
上图中的Reactor的基本结构是一个事件循环(event loop),以事件驱动(event-driven)和事件回调的方式实现业务逻辑,伪代码如下:
while (!done)
{
int retval = :poll(fds, nfds, timeout_ms); // select和epoll等多路复用器类似
if (retval < 0) {
// 处理错误哦,回调用户的error handler
} else if (retval > 0) {
// 处理IO事件(也可以处理通过timerfd的定时器事件),回调用户的IO event handler
}
}
上图中的acceptor的作用是:当监听描述符(listen fd)可读时。acceptor会接受客户端的连接请求,并将新建立的连接(描述符)注册到Reactor中,等待可读事件发生(本模式中只有一个Reactor,后面会降到多Reactor模式,在多Reactor模式中,acceptor会将新建立的连接根据一定规则注册到不同的Reactor中)
上面仅仅是一个粗略的模型,没有给出codec或者dispatcher,在实际的服务器实现中,codec和dispather是必不可少的。codec负责解析消息,处理消息可能出现的各种情况,比如,如果是收到了半条消息,那么不会触发消息事件回调,数据会停留在Buffer里面(数据已经读到Buffer中了),等待收到一个完整的消息再通知处理函数。 ,dispather则根据消息分发到不同的处理方法中。
此模式的特点: 由于只有一个线程,因此事件是顺序处理的,一个线程同时只能做一件事情,事件的优先级得不到保证。因为”从poll返回后” 到”下一次调用poll进入等待之前”这段时间内,线程不会被其他连接上的数据或者事件抢占。所以在使用这种模式时,需要避免业务逻辑阻塞当前IO线程。 redis就是采用的这种线程模型,在redis中,鉴于大部分操作,如GET、SET等,处理速度都很快,所以redis的整体性能还算不错,但是如果进行某些比较耗时的操作,如在数据量很大的情况下执行KEYS,会阻塞住IO线程,导致其他请求无法快速响应。也是基于这个原因某些Redis中间件方案(如twemproxy)会将这些耗时的操作禁用。
模式二: Reactor + 线程池(Thread Pool)
此模式的程序结构如下:
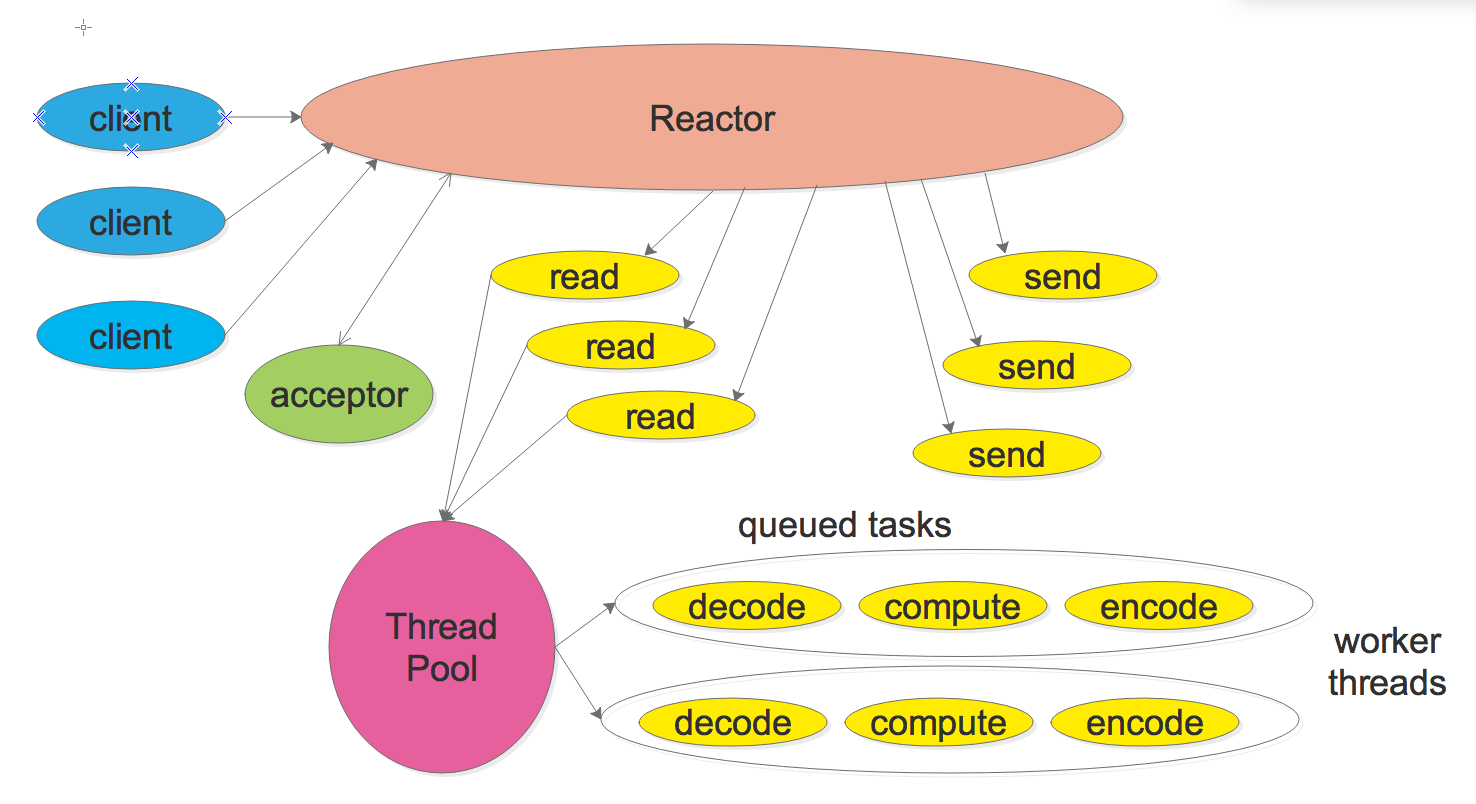
相比于模式一,此模式中收到请求后,不在Reactor线程计算,而是使用线程池来计算,这会充分的利用多核CPU。采用此模式时有可能存在多个线程同时计算同一个连接上的多个请求,算出的结果的次序是不确定的, 所以需要网络框架在设计协议时带一个id标示,以便以便让客户端区分response对应的是哪个request。
模式三: Multiple Reactors
此模式的程序结构如下:
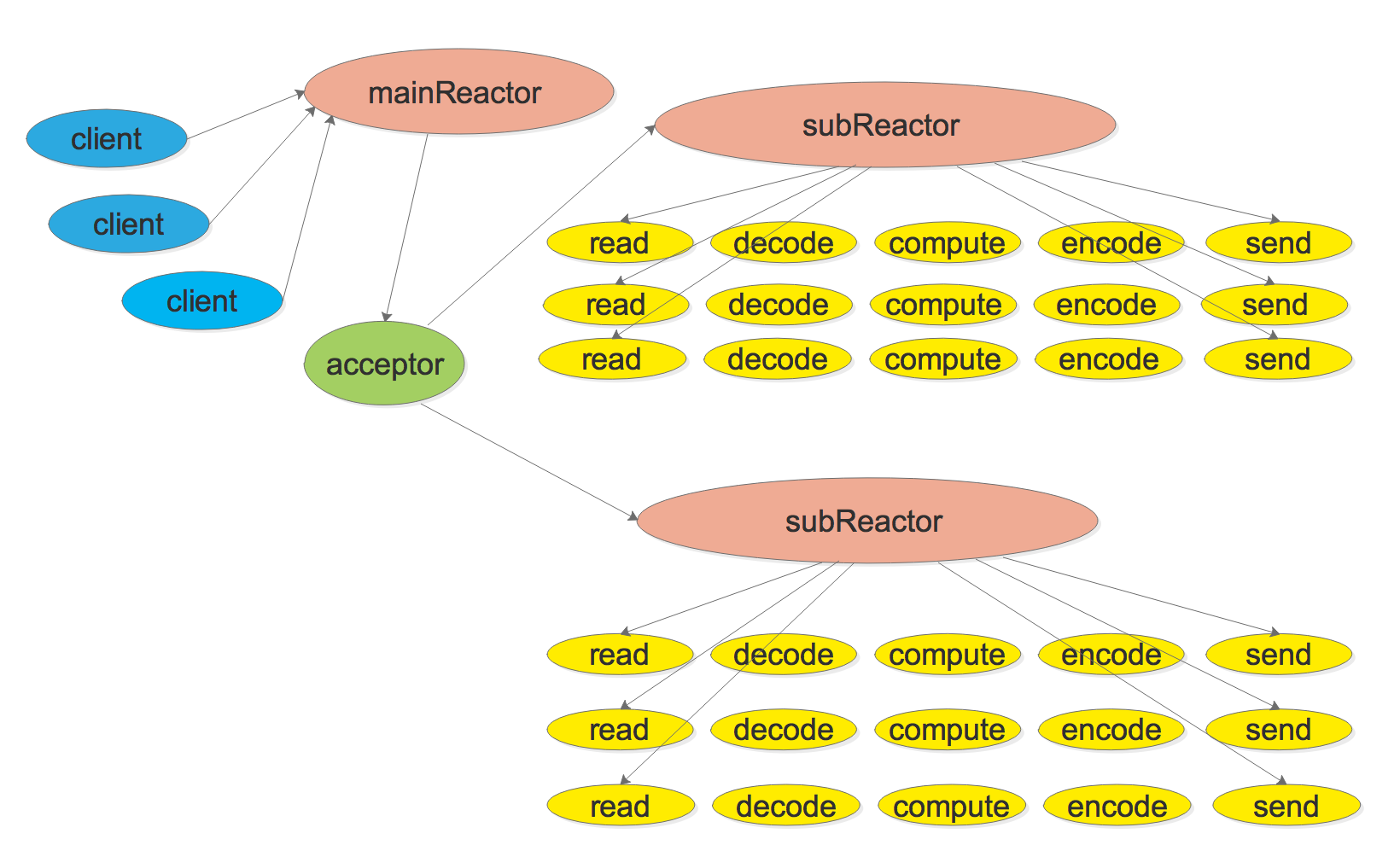 此模式的特点是one loop per thread, 有一个main Reactor负责accept连接, 然后把该连接挂在某个sub Reactor中(可以采用round-robin或者随机方法),这样该连接的所有操作都在哪个sub Reactor所处的线程中完成。多个连接可能被分配到多个线程中,充分利用CPU。在应用场景中,Reactor的个数可以采用
固定的个数,比如跟CPU数目一致。此模式与模式二相比,减少了进出thread pool两次上线文切换,小规模的计算可以在当前IO线程完成并且返回结果,降低响应的延迟。并可以有效防止当IO压力过大时一个Reactor处理能力饱和问题。纯转发的proxy服务适合使用这种模式
此模式的特点是one loop per thread, 有一个main Reactor负责accept连接, 然后把该连接挂在某个sub Reactor中(可以采用round-robin或者随机方法),这样该连接的所有操作都在哪个sub Reactor所处的线程中完成。多个连接可能被分配到多个线程中,充分利用CPU。在应用场景中,Reactor的个数可以采用
固定的个数,比如跟CPU数目一致。此模式与模式二相比,减少了进出thread pool两次上线文切换,小规模的计算可以在当前IO线程完成并且返回结果,降低响应的延迟。并可以有效防止当IO压力过大时一个Reactor处理能力饱和问题。纯转发的proxy服务适合使用这种模式
模式四: Multiple Reactors + 线程池(Thread Pool)
此模式的程序结构如下
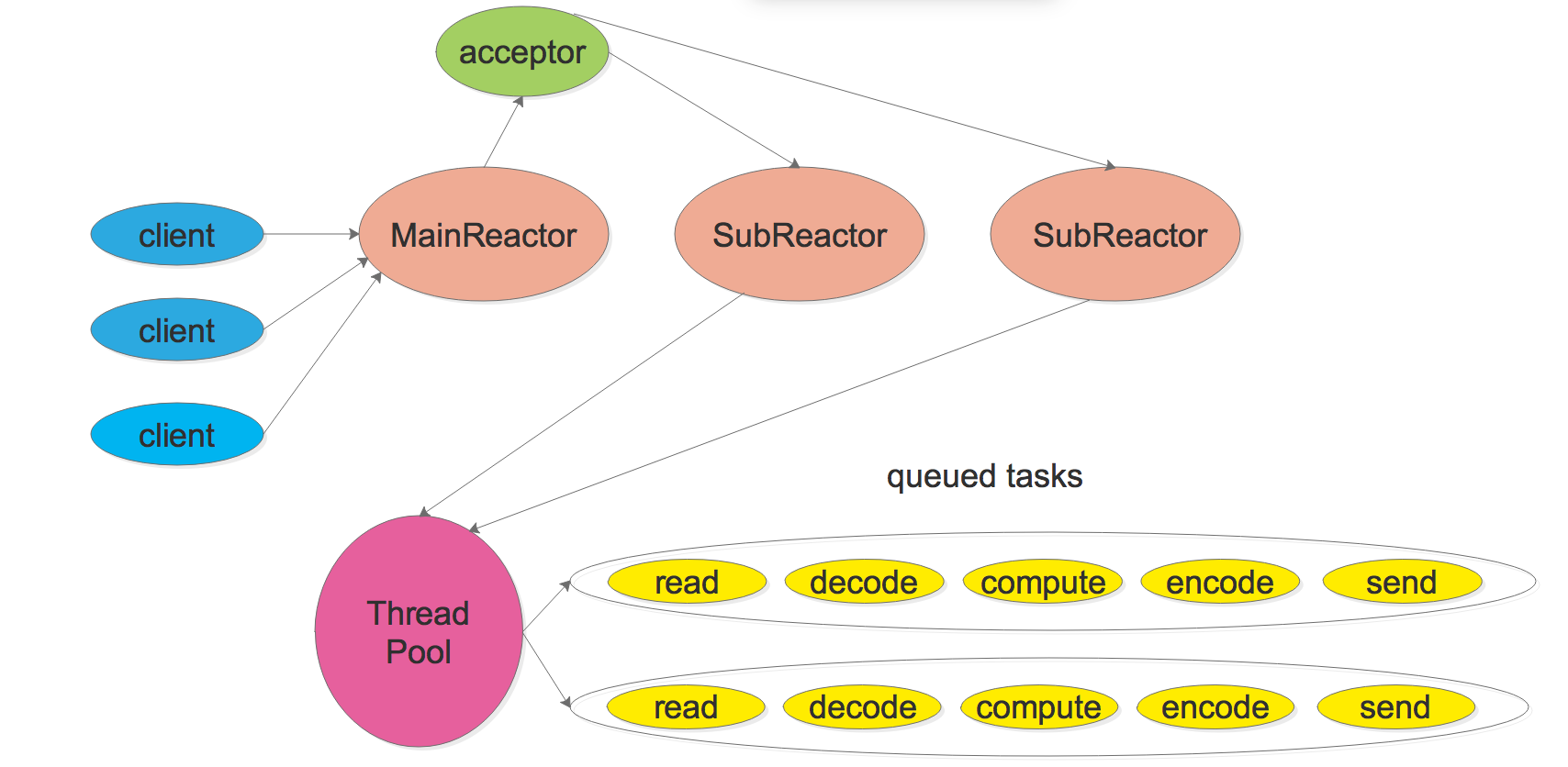 此模式是模式二和模式三的混合体,它既使用多个 reactors 来处理 IO,又使用线程池来处理计算。此模式适适合既有突发IO(利用Multiple Reactor分担),又有突发计算的应用(利用线程池把一个连接上的计算任务分配给多个线程)。
此模式是模式二和模式三的混合体,它既使用多个 reactors 来处理 IO,又使用线程池来处理计算。此模式适适合既有突发IO(利用Multiple Reactor分担),又有突发计算的应用(利用线程池把一个连接上的计算任务分配给多个线程)。
需要说明的一点是,前面介绍的四种Reactor模式在具体实现时为了简应该遵循的原则是:每个文件描述符只由一个线程操作。这样可以轻轻松松解决消息收发的顺序性问题,也避免了关闭文件描述符的各种race condition。一个线程可以操作多个文件描述符,但是一个线程不能操作别的线程拥有的文件描述符。这一点不难做到。epoll也遵循了相同的原则。Linux文档中并没有说明,当一个线程证阻塞在epoll_wait时,另一个线程往epoll fd添加一个新的监控fd会发生什么。新fd上的事件会不会在此次epoll_wait调用中返回?为了稳妥起见,我们应该吧对同一个 epoll fd的操作(添加、删除、修改等等)都放到同一个线程中执行。
模式参数选择
1. 一个程序到底是使用一个event loop还是多个event loop呢?
ZeroMQ手册给出的建议是,按照每千兆比特每秒的吞吐量配置一个event loop的比例来设置event loop的数目,即,在编写运行在千兆以太网上的网络程序时,用一个event loop就足以应付网络IO。如果程序本身没有计算量,主要瓶颈在于网络带宽,那么可以按照这条规则来办,只用一个event loop。 另一方面,如果程序的IO带宽较小,计算量较大,可以把计算放到thread pool中,也可以只用一个event loop。
2. 如何设置线程池的个数?
如果线程执行任务时,计算密集所占的时间比重为P(0 < P <= 1), 而系统中一共有C个CPU,为了让C个CPU跑满而又不过载,线程池大小的经验公式T=C/P。考虑到P值估的不准,T的最佳值可以上下浮动50%。 原理很简单,T个线程,每个线程占用P的CPU时间,加在一起刚好占满C个CPU,即T*P=C。
假设C=8, P=1.0:线程池里的任务完全是计算密集,那么T=8,只要8个活动线程就能让8个CPU饱和,再多也没用,因为CPU资源已经耗光了。
假设C=8,P=0.5:线程池的任务有一半是计算,有一半是在等待IO。那么T=16。考虑操作系统能灵活合理的调度slepping/writing/running线程,那么大概16个50%繁忙的线程能让8个CPU忙个不停。启动更多的线程并不能提高吞吐量,反而因为增加上下文切换的开销而降低性能。
如果P<0.2这个公式就不合适了,T可以取一个固定的值,比如5*C。另外,公式里的C不一定是CPU总数,可以使“分配给这项任务的CPU数目”,比如在8个机器上分出4个核来做一项任务,那么C=4。