Compaction操作是LSM的核心,所谓Compaction就是将现有的SST文件进行压缩合并,生成新SST文件过程。 Compaction操作的主要目的有两个:
- 通过减少文件的增长量来保证读操作的性能
- 通过合并文件来删除相同Key的重复更新的或者删除的Key。
由于与Compaction相关的逻辑贯穿在整个LevelDB代码库,扣起细节来会太过繁琐,所以本文力求在整体上对Compaction分析,实现细节上不会有过多阐述。
Compaction分类
LevelDB中有两种Compaction:
- 将内存中的immutable dump到磁盘,生成新SST文件
- 按一定策略从现有SST文件中选取一些文件文件合并成新文件
Compaction触发条件
满足一下的任意一种条件都会需要进行Compaction操作:
-
每个level中SST文件总数目或者总大小阈值(表现为compaction_score_ >= 1)
在LevelDB中,如果level-0文件数目达到kL0_CompactionTrigger,或其他level的文件总大小达到一定阈值MaxBytesForLevel(),均需要进行Compaction操作。 判断文件是否达到阈值的函数为VersionSet::Finalize()。
-
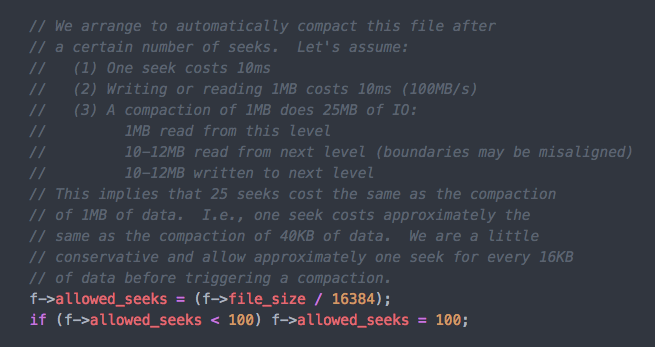
某个SST文件被读取次数到达阈值(FileMetaData::allowed_seeks)
allowed_seeks的设置在VersionSet::Builder::Apply()中,设置算法如下
- 概率性的触发Compaction,这个是通过迭代器查找Key时触发,后面会有讲解
- 手动触发Compaction
说明:当条件1和条件2同时满足时,优先按照条件1选取Compaction文件(具体见:VersionSet::PickCompaction())。
何时检查是否需要Compaction
LevelDB通过调用DBImpl::MaybeScheduleCompaction()函数来判断是否需要Compaction,如果需要,则调用Env::Schedule唤起Compaction。那么,调用MaybeScheduleCompaction()的时机有哪些呢?
-
数据库Open
之所以在数据库打开时检查是否需要Compaction是因为存在以下可能:
- 打开一个已经存在的数据库时,可能需要从WAL log文件中恢复数据到Memtable,如果Memtable的大小在重新打开时设置的比上次小,则有可能产生多次immutable, 进而生成多个新的SST文件(immutable dump生成),达到Compaction阈值(kL0_CompactionTrigger)
- 上次数据库关闭时正好已经触发了Compaction操作,只是操作还没有来得及执行或执行到一半,所以在数据库再次打开时重新执行Compaction操作。
-
Write调用
之所以每次Write操作时都要检查是否Compaction是因为存在以下可能:
- Write操作时可能Memtable大小已经达到最大阈值,进而生成immutable,这时候需要Compaciton将immutable dump成SST文件
- Write操作太快,Compaction速度赶不上Write速度,导致Level0层积累的文件达到了Compaction的阈值(kL0_CompactionTrigger)
-
Get调用
之所以每次Get操作时都要检查是否Compaction是因为Get()调用可能会使某个SST文件达到 allowed_seeks阈值
-
Iterator调用
迭代器实例(DBIter)在每执行一次Next()或Prev()操作时,都会对读取的字节数(key.size()+value.size())进行计数(bytes_counter_)。当bytes_counter_达到一个累积值时(bytes_counter_的设置为以kReadBytesPeriod为平均值的随机数),就会对迭代器的当前Key进行探测,检查是否有相同的Key存在不同的文件中,当发下这种情况,则会将发现此Key的第一个文件设置成下次要Compaction的文件。
-
Compcation操作后
上一次的Compaction操作可能会在某个Level中生成很多新文件,这些新文件可能又会达到Compaction阈值,所以每次Compaction操作之后会检查是否需要再次Compaction
从上面的分析看出引发Compaction的操作无处不在,Get、Write、Iterator都可能引发Compaction。 MaybeScheduleCompaction()原型如下:
void DBImpl::MaybeScheduleCompaction() {
mutex_.AssertHeld();
if (bg_compaction_scheduled_) {
// Already scheduled
} else if (shutting_down_.Acquire_Load()) {
// DB is being deleted; no more background compactions
} else if (!bg_error_.ok()) {
// Already got an error; no more changes
} else if (imm_ == NULL &&
manual_compaction_ == NULL &&
!versions_->NeedsCompaction()) {
// No work to be done
} else {
bg_compaction_scheduled_ = true;
env_->Schedule(&DBImpl::BGWork, this);
}
}
此函数会检查是否有immutable需要dump磁盘(imm_ == NULL ?)或者现有的的SST文件是否需要合并(versions_->NeedsCompaction() ?), 如果条件满足且当前没有Compaction任务,就会通过调用env_->Schedule(&DBImpl::BGWork, this)来启动后台线程进行合并操作。
下面具体看下将immutable 落地成SST文件及SST文件之间Compaction的过程。
Immutable Compaction
前面的文章中讲过,当往LevelDB中写入(Put)一条记录的时,会先将此记录追加到Log文件中,之后再插入Memtable,当Memtable占用的内存达到指定阈值后,LevelDB会生成新的Log文件及Memtable文件,并将原来的Memtable转化为Immutable Memtable(只读),待后续落地成SSTable文件。落地成SSTable文件的实现逻辑主要在DBImpl::WriteLevel0Table()中
- 将Memtable中的键值对按照SST格式落地成一个SST文件
-
调用Version::PickLevelForMemTableOutput()来确定新建的SST文件所属的level
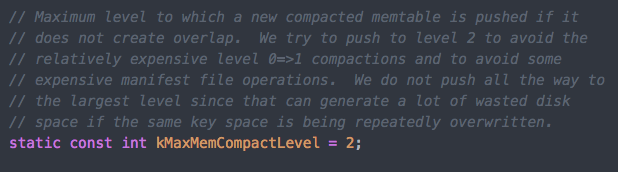
我们知道,在LevelDB中除了level0中的文件key可以重叠外,其他level中的文件key是不重叠的。所以在为新SST文件选择level时,如果新SST文件与level0中的文件不存在key的重叠且有比level0更合适的level,它会优先放到其他level,没有其他合适的level才会放到level0。需要注意的是,memtable文件最多会放到level2中,而不会放到更多的level,原因在kMaxMemCompactLevel的定义处(dbformat.h)有解释,最主要的原因还是尽量减少Compaction次数及磁盘空间的浪费。
File Compaction
Compaction以文件为操作单元,即每次Compaction只能将整个SST文件进行合并,而不是选取文件中某个范围进行合并。合并时将选取Level L 中的若干SST文件,跟Level (L+1)中的若干SST文件进行合并,以新文件的形式添加到Level(L+1)中,并删除输入文件。合并逻辑入口为DBImpl::BackgroundCompaction(),主要逻辑如下:
- 通过VersionSet::PickCompaction() 选择要合并的Level L(current_->compaction_level_)及Leve L中的文件
- 通过VersionSet::SetupOtherInputs()选择Level L+1 中与Level L中选取的文件存在Key重叠的文件(此时可能会扩大Level L中文件数量)。
- 调用DBImpl::DoCompactionWork()对Level L 及 Level L+1 中文件进行合并 合并的流程是通过构造一个MergingIterator来将所有的输入文件组织成一个有序的输入流遍历迭代器,将Level L 及Level L+1中所有数据dump成Level+1中的新文件。遍历迭代器时会丢弃已经删除的数据(kTypeDeletion)及过期的数据。需要注意的是:每遍历一个Key时都会先检查immutable是否存在,如果存在的话会优先将其dump成SST文件以保证写操作不会被阻塞。
关于迭代器
不管是Immutable Compaction还是File Compaction, 在Compaction过程中需要通过Iterator对指定的文件集合进行按需遍历,都使用了大量的迭代器。了解迭代器对从代码上理解Compaction有很大帮助,这里大概再介绍下LevelDB中的迭代器。
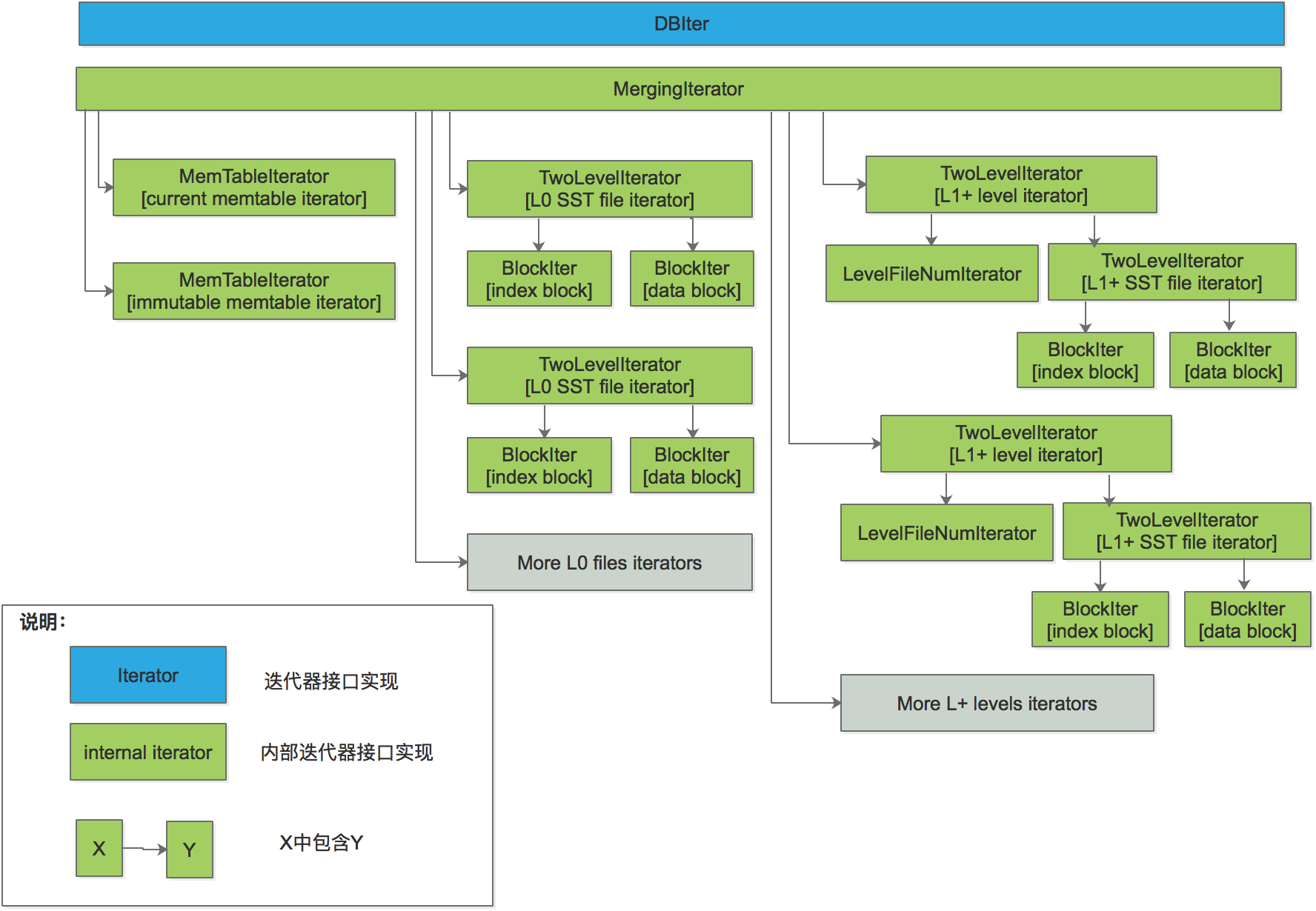
上图是LevelDB中整个迭代器的关系。大致分为DBIter、MergingIterator、MemtableIterator、TwoLevelIterator、BlockIter。
DBIter
定义:db/db_iter.cc
DBIter是一个InternalIterator的封装,即是MergingIterator的封装。DBIter的工作是解析由InternalIterator返回的InternalKeys,将其变成UserKeys(InternalKey和UserKey的区别可以参照这篇文章) 举例: InternalIterator返回如下结果:
InternalKey(user_key="Key1", seqno=10, Type=Put) | Value = "KEY1_VAL2"
InternalKey(user_key="Key1", seqno=9, Type=Put) | Value = "KEY1_VAL1"
InternalKey(user_key="Key2", seqno=16, Type=Put) | Value = "KEY2_VAL2"
InternalKey(user_key="Key2", seqno=15, Type=Delete) | Value = "KEY2_VAL1"
InternalKey(user_key="Key3", seqno=7, Type=Delete) | Value = "KEY3_VAL1"
InternalKey(user_key="Key4", seqno=5, Type=Put) | Value = "KEY4_VAL1"
通过DBIter,会取最新的Key且有效的Key值,然后暴露给用户的结果如下:
Key="Key1" | Value = "KEY1_VAL2"
Key="Key2" | Value = "KEY2_VAL2"
Key="Key4" | Value = "KEY4_VAL1"
MergingIterator
定义: table/merger.cc
MergingIterator由许多子迭代器构成,在MergingIterator会将所有子迭代器显示为一个排序流。 举例: 下面是MergingIterator子迭代器的展开形式
= Child Iterator 1 =
InternalKey(user_key="Key1", seqno=10, Type=Put) | Value = "KEY1_VAL2"
= Child Iterator 2 =
InternalKey(user_key="Key1", seqno=9, Type=Put) | Value = "KEY1_VAL1"
InternalKey(user_key="Key2", seqno=15, Type=Delete) | Value = "KEY2_VAL1"
InternalKey(user_key="Key4", seqno=5, Type=Put) | Value = "KEY4_VAL1"
= Child Iterator 3 =
InternalKey(user_key="Key2", seqno=16, Type=Put) | Value = "KEY2_VAL2"
InternalKey(user_key="Key3", seqno=7, Type=Delete) | Value = "KEY3_VAL1"
MergingIterator会将其对外展示成如下的排序流
InternalKey(user_key="Key1", seqno=10, Type=Put) | Value = "KEY1_VAL2"
InternalKey(user_key="Key1", seqno=9, Type=Put) | Value = "KEY1_VAL1"
InternalKey(user_key="Key2", seqno=16, Type=Put) | Value = "KEY2_VAL2"
InternalKey(user_key="Key2", seqno=15, Type=Delete) | Value = "KEY2_VAL1"
InternalKey(user_key="Key3", seqno=7, Type=Delete) | Value = "KEY3_VAL1"
InternalKey(user_key="Key4", seqno=5, Type=Put) | Value = "KEY4_VAL1"
MemtableIterator
定义:db/memtable.cc
它用于完成对memtable或者immutable memtable的迭代遍历,本质上是一个基于SkipList的迭代器。
#####BlockIter
定义:table/block.cc
由于SST文件的块数据是按序排列且不可变的,我们可以将其加载到内存中,并为这些排序数据创建一个BlockIter。
TwoLevelIterator
定义:table/two_level_iterator.cc
TwoLevelIterator由两个迭代器组成:
- First level iterator(index_iter_)
- Second level iterator(data_iter_)
index_iter_是指向Index block的迭代器。 data_iter_是指向Data block的迭代器。下面看一下一个SST文件的简化表示, 下面有4个数据块及1个索引快
[Data block, offset: 0x0000]
KEY1 | VALUE1
KEY2 | VALUE2
KEY3 | VALUE3
[Data Block, offset: 0x0100]
KEY4 | VALUE4
KEY7 | VALUE7
[Data Block, offset: 0x0250]
KEY8 | VALUE8
KEY9 | VALUE9
[Data Block, offset: 0x0350]
KEY11 | VALUE11
KEY15 | VALUE15
[Index Block, offset: 0x0500]
KEY3 | 0x0000
KEY7 | 0x0100
KEY9 | 0x0250
KEY15 | 0x0500
可以通过创建TwoLevelIterator来读取此文件,当通过TwoLevelIterator来查找KEY8时,第一步通过使用index_iter_确定哪个块会包含此键。 上面的例子中,第3个数据块可能包含此键,所以data_iter_会指向偏移为0x0250的位置。之后会使用data_iter_在相应的数据块中找到需要的键值对。
Compaction基本分析完成。
参考:
LevelDB源码