LevelDB插入一条记录时,采用WAL(write ahead logging)方式,先顺序写到磁盘日志中,然后写入Memtable。这种方式可以保证程序异常结束后数据不丢失,并且由于采用了顺序写+内存写的方式,写性能很高。
LevelDB支持单条写以及批量写的操作,用法分别如下:
一次插入单条记录
db->Put(leveldb::WriteOptions(), key2, value);
WriteBatch形式插入多条记录
leveldb::WriteBatch batch;
batch.Delete(key1);
batch.Put(key2, value);
s = db->Write(leveldb::WriteOptions(), &batch);
在底层实现上,Put操作也是通过将记录写入WriteBatch进行的。
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) {
WriteBatch batch;
batch.Put(key, value);
return Write(opt, &batch);
}
来看下WriteBatch的定义及实现
WriteBatch将一系列的操作原子性的应用到数据库中,WriteBatch中的所有的更新按照他们被添加到WriteBatch中的顺序执行,比如,当下面的操作执行完成后,”key”的值将会为”v3”:
batch.Put("key", "v1");
batch.Delete("key");
batch.Put("key", "v2");
batch.Put("key", "v3");
WriteBatch的定义如下:
class WriteBatch {
public:
WriteBatch();
~WriteBatch();
// Store the mapping "key->value" in the database.
void Put(const Slice& key, const Slice& value);
// If the database contains a mapping for "key", erase it. Else do nothing.
void Delete(const Slice& key);
// Clear all updates buffered in this batch.
void Clear();
// Support for iterating over the contents of a batch.
class Handler {
public:
virtual ~Handler();
virtual void Put(const Slice& key, const Slice& value) = 0;
virtual void Delete(const Slice& key) = 0;
};
Status Iterate(Handler* handler) const;
private:
friend class WriteBatchInternal;
std::string rep_; // See comment in write_batch.cc for the format of rep_
// Intentionally copyable
};
从定义上看到,WriteBatch通过一个string(rep_)来保存所有的记录,WriteBatch它的结构如下:
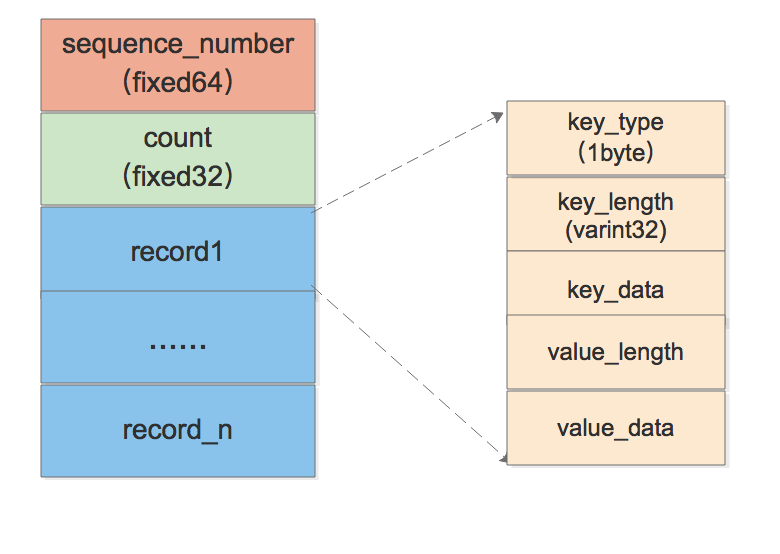
说明:
- sequence_number: 版本号,值=(全局最新版本号+1),在调用Write时填充( WriteBatchInternal::SetSequence(updates, last_sequence + 1) ),用于为WriteBatch中的所有操作生成一个版本号。WriteBatch里的每一次Put或者Delete操作的版本号都是在这个这个sequence_number基础上加1生成。当WriteBatch中的所有操作都执行完成后,全局版本号会增加count(last_sequence += WriteBatchInternal::Count(updates))
- count: 此WriteBatch中记录的个数
- key_type: 为kTypeDeletion 或 kTypeValue 中的一种。当key_type为kTypeDeletion时,value_length及value_data为空。
当调用Write()函数将WriteBatch中的一系列操作写入数据库时,会先将数据以上述的格式写入Log中,以便数据恢复。 下面看下Write函数逻辑:
Status DBImpl::Write(const WriteOptions& options, WriteBatch* my_batch) {
Writer w(&mutex_);
w.batch = my_batch;
w.sync = options.sync;
w.done = false;
MutexLock l(&mutex_);
writers_.push_back(&w);
while (!w.done && &w != writers_.front()) {
w.cv.Wait();
}
if (w.done) {
return w.status;
}
// May temporarily unlock and wait.
Status status = MakeRoomForWrite(my_batch == NULL);
uint64_t last_sequence = versions_->LastSequence();
Writer* last_writer = &w;
if (status.ok() && my_batch != NULL) { // NULL batch is for compactions
WriteBatch* updates = BuildBatchGroup(&last_writer);
WriteBatchInternal::SetSequence(updates, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(updates);
// Add to log and apply to memtable. We can release the lock
// during this phase since &w is currently responsible for logging
// and protects against concurrent loggers and concurrent writes
// into mem_.
{
mutex_.Unlock();
status = log_->AddRecord(WriteBatchInternal::Contents(updates));
bool sync_error = false;
if (status.ok() && options.sync) {
status = logfile_->Sync();
if (!status.ok()) {
sync_error = true;
}
}
if (status.ok()) {
status = WriteBatchInternal::InsertInto(updates, mem_);
}
mutex_.Lock();
if (sync_error) {
// The state of the log file is indeterminate: the log record we
// just added may or may not show up when the DB is re-opened.
// So we force the DB into a mode where all future writes fail.
RecordBackgroundError(status);
}
}
if (updates == tmp_batch_) tmp_batch_->Clear();
versions_->SetLastSequence(last_sequence);
}
while (true) {
Writer* ready = writers_.front();
writers_.pop_front();
if (ready != &w) {
ready->status = status;
ready->done = true;
ready->cv.Signal();
}
if (ready == last_writer) break;
}
// Notify new head of write queue
if (!writers_.empty()) {
writers_.front()->cv.Signal();
}
return status;
}
Write实现上针对多线程并发写做了优化。它没有使用一个Mutex锁住整个Write函数,而是采用了“条件变量+写队列+一个写线程代理其他写线程”方式来减小锁的粒度,提高写性能: 每次执行写操作时,LevelDB首先将待写入的WriteBatch放到writers队列中(定义:std::deque<Writer*> writers_)然后判断队列中是否存在由其它线程放入的待写入DB的WriteBatch,如果存在的话则将此写线程设置为等待条件变量激活(这时候mutex_锁已经被释放,其他写线程可以继续往writers队列中添加任务,增加写线程的并发性),如果队列中不存在其它待写入DB的WriteBatch,表示当前此DB只有一个写线程,则不需要等待条件变量,直接往下执行。写线程被激活后(或者只有一个写线程)会先判断是否需要“MakeRoomForWrite“(21行,延迟写、生成新memtable、唤醒compaction等,后面文章会详细讲解), 然后将writers队列中的WriteBatch按照一定策略(1. 避免每次写入过多数据占用磁盘带宽; 2.只合并options.sync设置相同的WriteBatch)合并到一起(BuildBatchGroup()),分别写到Log及Memtable中(第31行及40行)。最后将已经写入到DB的WriteBatch状态设置为done并激活等待条件变量的线程(第55-69行)。
写操作基本流程分析完毕。