本文分topic讲解Linux环境下文件I/O中涉及到的知识点,温故知新,更深刻的了解文件I/O
topic1: 硬盘构造(为什么磁盘顺序读写比随机读写更快)
传统磁盘是由盘片构成,每个盘片表面都覆盖着磁性记录材料。盘片中央有一个可以旋转的主轴,它使得盘片以固定的旋转速率(rotational rate)旋转,通常是5400 ~ 15000转每分钟(Revolution Per Minute, RPM)。磁盘通常包含一个或者多个这样的盘片,并封装在一个密封容器内。每个盘片表面是由一组成为磁道(track)的同心圆组成。每个磁道被划分为一组扇区(sector), 每个扇区包含相等数量的数据位(通常是512字节),数据编码在扇区上的磁性材料中。扇区之间由由一些间隙(gap)隔开。磁盘用读/写头(read/write head)来读写存储在磁性表面的位,读/写头连接到一个传动臂(actuator arm)一端,通过移动传动臂,驱动器可以将读/写头定位在盘面上的任何磁道上,这样的机械运动成为寻道(seek)。下面几个图可以对磁盘结构有更直观的理解:
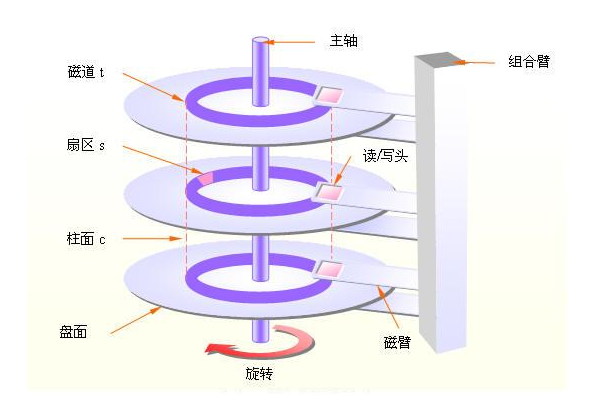
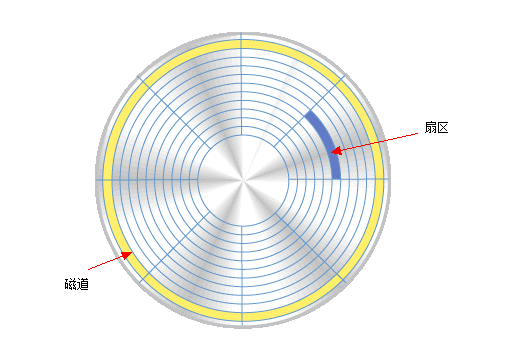
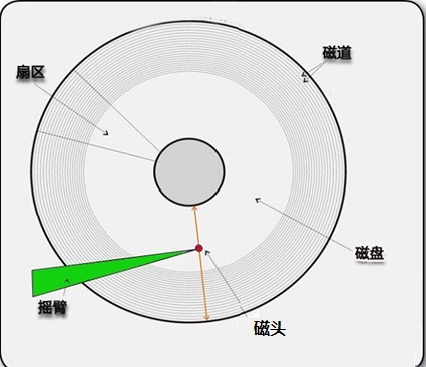

磁盘以扇区大小的块来读写数据。对扇区的访问时间,有三个主要部分: 寻道时间、旋转时间和传送时间:
-
寻道时间: 为了读取某个目标扇区的内容,传动臂首先将读/写头定位到包含目标扇区的磁道上。移动传动臂所需的时间为寻道时间。寻道时间依赖于读/写头以前的位置和传动臂在盘面上移动的速度。通常一次寻道时间平均为3~9ms。最大时间可以达到20ms。
-
旋转时间: 一旦读/写头定位到了期望的磁道,驱动器等待目标扇区的第一位旋转到读写头下,这个步骤的性能依赖于当读写头到达目标扇区时盘面的位置和磁盘的旋转速度。通常使用磁盘旋转一周所需时间的1/2表示,在最坏的情况下,读写头刚刚错过了目标扇区,必须等待磁盘转一圈。7200 rpm的磁盘平均旋转延迟大约为4.17ms,而转速为15000 rpm的磁盘其平均旋转延迟为2ms。
-
传送时间: 当目标扇区的第一位位于读/写头下时,驱动器就可以开始读或者写该扇区的内容了,一个扇区的传送时间依赖于旋转速度和每条磁道的扇区数目,简单计算时可忽略。
在顺序读写的时候,寻道和旋转步骤只需要执行一次,剩下的全是数据传输所需要的固有开销;而每次随机读写的时候,寻道和旋转步骤都需要执行(不考虑操作系统读写缓冲),所以,机顺序读写比随机读写更快。 需要说明的是,与传统的磁盘相比,固态磁盘(SSD)并没有机械装置,也就没有了传统磁盘的寻道时间和旋转时间,
需要说明的是,固态驱动器(solid state drives SSDs)没有旋转磁盘设备,全部都是采用闪存。像闪存这样的固态驱动器的查找定位时间要远远低于磁盘驱动器的时间,因为在查找给定数据块时没有“旋转”代价。SSDs是以类似随机访问内存的方式来索引,它不但可以非常高效的读取大块连续数据,随机访问的耗时也很小,可以提供非常高的随机读取能力(但是它随机写性能则比随机读慢一个数量级)。
在多线程并发读写磁盘的情况下,磁盘I/O效率将大大下降,可以 减少多进程或者多线程对磁盘的并发读写,比如日志打印程序,可以使用专门磁盘I/O线程来对磁盘读写。
topic2: 内核I/O基本概念
内核I/O涉及到的基本概念有扇区、物理块、逻辑块、块缓存、页缓存等。
扇区、物理块与逻辑块
硬盘基于用柱面(cylinders)、磁头(heads)和扇区(section)几何寻址方式来获取数据,这种方式也被称为CHS寻址。为了定位某个特定数据单元在磁盘上的位置,驱动程序需要知道三个信息:柱面、磁头和扇区的值。现代操作系统不会直接操作硬盘的柱面、磁头和扇区。硬盘驱动将每个柱面/磁头/扇区的三元组映射成唯一的块号(也叫物理块),即一个物理块对应一个扇区。文件系统是软件领域的概念,他们操作的单元叫做逻辑块,也叫文件系统块或者块(block)。逻辑块的大小是物理块大小的整数倍。换句话说,文件系统的逻辑块由多个连续的磁盘物理块组成也就是多个连续的扇区组成。一般一个扇区(物理块)存储512字节,一个文件系统块(block)为4096个字节,即连续8个扇区(物理块)组成一个文件系统块(block)。块(block)是文件系统中最小存储单元的抽象。 在内核中,所有的文件系统都是基于块来执行的。实际上,块是I/O的基本概念,因此,所有的I/O操作都是在块大小或者块大小的整数倍上执行,也就是说,也许你想要读取一个字节,实际上需要读取整个块,想写入4.5个块的数据?你需要写入5个块的数据,也就是说读取最后一块整块的数据,更新(删掉)后半部分内容,然后把整个块出去。
如下图所示,一个文件对应多个可能不连续的文件系统块(block)。
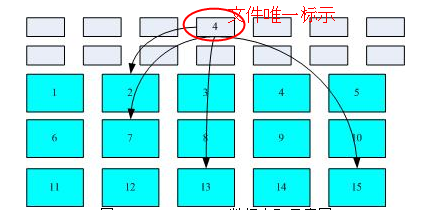 上图采用索引式文件系统,inode号为4的文件对应了2,7,13,15这四个不连续的block。
上图采用索引式文件系统,inode号为4的文件对应了2,7,13,15这四个不连续的block。
块缓存(buffer cache)与页缓存(page cache)
Linux实现中,文件Cache分两个层面,一个是页缓存, 另一个是块缓存,内存管理系统和VFS(虚拟文件系统)只与页缓存交互 每一个页缓存包含若干块缓存。内存管理系统负责维护每项页缓存的分配和回收,同时在使用memory map方式访问时负责建立映射。VFS负责页缓存与用户空间的数据交换。而具体文件系统则一般只与块缓存交互,它们负责在外围存储设备和块缓存之间交换数据。块缓存的大小通常由块设备的大小来决定,取值范围在512B~4KB之间,取块设备大小的最大公约数。 一个页缓存中包含一个或多个块缓存。下图是文件/缓存等关系
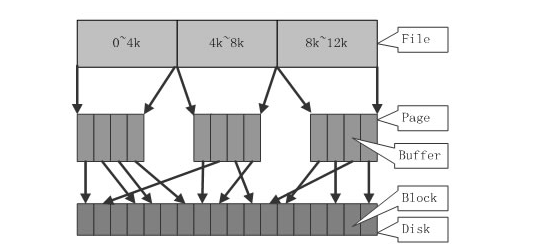
页缓存:是通过内存保存最近在磁盘文件系统上访问过的数据的一种方式。相对于当前的处理器速度而言,磁盘访问速度过慢。通过在内存中保存被请求的数据,内核后续对相同的数据请求就可以从内存中读取,避免了重复访问磁盘。 页缓存利用了“时间局部性(temporal locality)”原理,它是一种“引用局部性(locality of reference)”,时间局部性的概念基础是认为刚被访问过的资源在不久后再次被访问的概率很高。在第一次访问时对数据进行缓存,虽然消耗了内存,但避免了后续代价很高的磁盘访问。 内核查找文件系统数据时,会首先查找页缓存。只有在缓存找不到数据时,内核才会调用存储子系统从磁盘读取数据。因此,第一次从磁盘读取数据后,就会保存到页缓存中,应用在后续读取时都是从页缓存中读取并返回。页缓存上的所有操作都是透明的,从而保证数据总是有效的。 另一种引用局部性是“空间局部性(sequential locality)”,其理论基础是认为数据往往是连续访问的。基于这个原理,内核实现了页缓存预读技术。预读是指在每次读请求是,从磁盘数据中读取更多的数据到页缓存。当内核从磁盘中读取一块数据时,它还会读取接下来一两块数据。一次性读取较大的连续数据块会比较高效,因为通常不需要磁盘寻址。如果进程继续对连续块提交新的读请求,内核就可以直接返回预读的数据,而不用再次发起磁盘I/O请求。内核对预读的管理是动态变化的。如果内核发现一个进程一直使用预读的数据,他就会增加预读窗口,从而预读更多的数据。预读窗口最小16KB,最大128KB。反之,如果内核发现预读没有带来任何有效的命中–也就是说,应用随机读取文件,而不是连续的–它可以把预读关掉。
页回写:内核通过缓冲区来延迟写操作。当进程发起写请求(系统write调用),数据被拷贝到缓冲区,并将该缓冲区标记为”脏”缓冲区,这意味着内存的拷贝要比磁盘上的新。此时写请求就可以返回了。如果后续对同一份数据块有新的写请求,缓冲就会更新成新的数据。对该文件的其他部分的写请求则会开辟新的缓冲区。 最后,那些“脏”缓冲区需要写到磁盘上,将磁盘文件和内存数据同步。这个过程就是所谓的“回写”。以下两个情况会出发回写:
- 当空闲内存小于设定的阈值时,“脏”缓冲区就会回写到磁盘上,这样被清理的缓冲区就会被移除,释放内存空间
- 当“脏”缓冲区的时常超过设定的阈值时,该缓冲区就会回写到磁盘。通过这种方式,可以避免数据一直是“脏”数据
回写是由一组称为flusher的内核线程来执行的。当出现以上两种场景之一时,flusher线程被唤醒,并开始将“脏”缓冲区
写回到磁盘,直到不满足回写的触发条件。
可能存在多个flusher线程同时执行回写。多线程是为了更好的利用并行性,避免拥塞。拥塞避免(congestion voidance)机制确保在等待向某个设备进行写操作时,还能支持其他的写操作。如果其他块设备存在脏缓冲区,不同flusher线程会充分利用每一块设备。
可以通过cat /proc/meminfo来查看脏数据大小
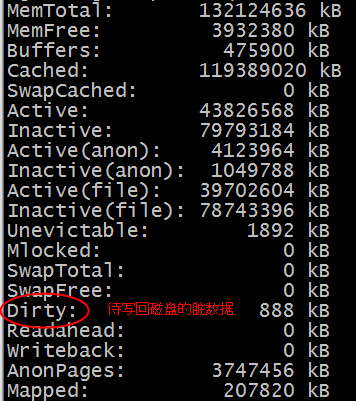 Dirty:888KB表示当前有888KB的数据缓存在page cache,在等待后台线程刷入磁盘。
在Linux中,延迟写和缓冲子系统使得写操作性能很高,其代价是如果电源出现故障,可能会丢失数据。为了避免这种风险,确保已经写到了磁盘上, 可以调用同步I/O。
Dirty:888KB表示当前有888KB的数据缓存在page cache,在等待后台线程刷入磁盘。
在Linux中,延迟写和缓冲子系统使得写操作性能很高,其代价是如果电源出现故障,可能会丢失数据。为了避免这种风险,确保已经写到了磁盘上, 可以调用同步I/O。
topic3 内核I/O调度器
现代操作系统中,磁盘和系统其他组件的性能差距很大,而且这种差距还在增大。磁盘性能最慢的部分在于把读写头(即)磁头从磁盘的一个位置移动到另一个位置(seek)”。在实际应用中,很多操作是以处理器周期(大概是1/3纳秒)来衡量,而单次磁盘查找定位平均需要8毫秒以上,这个值虽然不大,但却是CPU周期的2500万倍。由于磁盘驱动和系统其他组件在性能上的巨大差异,如果每次有I/O请求时,都直接把这些I/O请求发送给磁盘,效率会非常低下。因此,现在操作系统内核实现了I/O调度器(I/O Scheduler),通过操作I/O请求的服务顺序以及服务时间点,最大程度的减小磁盘寻址次数和移动距离。I/O调度器尽力将磁盘访问性能损失控制在最小。I/O调度器实现两个基本操作:合并(merging)和排序(sorting)。
-
合并: 合并操作将两个或者多个相邻的I/O请求过程合并为一个。考虑两次请求,一次读取第5号物理块,第二次读取6号和7号物理块上的数。这些请求被合并为一个对块5到7的操作。总的I/O吞吐量可能一样,但是I/O的次数减少了一半。
-
排序: 排序操作选取两个操作中相对更重要的一个,并按照块号递增的顺序重新安排等待I/O请求,比如说I/O操作要访问块52/109和7,I/O调度这三个请求以7/52/109的顺序进行排序。如果还有一个请求要访问81,他将被插入到访问52和109中间。然后I/O调度器按他们在队列中的顺序统一调度7/52/81/109。按这种方式,磁头的移动距离最小。磁头以平滑、线性的方式移动,而不是无计划的移动。因为寻址是I/O操作中代价最高的一部分,改进该操作会使I/O性能获得提升。 如果I/O调度器总是以插入方式对请求进行排序,可能会”饿死”块号值较大的访问请求,可能会极大影响系统性能。因此I/O调度器实现了Deadline/Anticipatory/CFQ等I/O调度器来避免”饿死”现象。 需要说明的是,对于SSDs,对I/O请求排序带来的好处不是很明显,这些设备很少使用I/O调度器。对于SSDs,很多系统采用Noop I/O调度器机制,即只提供合并功能,而不对请求排序。
topic4: 同步I/O
Linx下主要有fsync()和fdatasync()及sync()三个同步I/O命令
#include <unistd.h>
int fsync(int fd);
int fdatasync(int fd);
void sync(void)
系统调用fsync()可以确保和文件描述符fd所指向的文件相关的缓冲数据都会回写到磁盘上
fdatasync()的功能和fsync()类似,区别在于fdatasync()只会写入数据以及以后要访问文件所需要的元数据。例如, 调用fdatasync()会写文件的大小,因为以后要读取该文件需要文件大小这个属性。fdatasync()不保证非基础的元数据也 写到磁盘上,因此一般而言,它执行更快。对于大多数使用场景,除了最基本的事务外,不会考虑元数据如文件修改时间戳,因此fdatasync()就能够满足需求,而且执行更快
fsync()通常会涉及至少两个I/O操作: 一是回写修改的数据,而是更新索引节点的修改时间戳。因为索引节点和文件数据在磁盘上可能不是紧挨着的–因此会带来很高的seek操作–在很多场景下,关注正确的事务顺序,但是不包括那些对于以后访问文件无关紧要的元数据(比如修改时间戳),使用fdatasync()是提高性能的简单方式。 这两个函数都不保证任何已经更新的包含该文件的目录项会同步到磁盘上。这意味着如果文件链接最近刚更新,文件数据可能会成功写入磁盘,但是却没有更新的相关的目录中,导致文件不可用。为了保证对目录项的更新也都同步到磁盘上,必须对文件目录也调用fsync()进行同步。
Linux sync() 系统调用用来对磁盘上的所有缓冲区进行同步,虽然效率不高,但是还是被广泛应用,该函数没有参数,也没有返回值,但是总是成功返回,并确保所有的缓冲区–包括数据和元数据–都能够写入到磁盘。
注意,当系统繁忙时,sync()操作可能需要几分钟甚至更长的时间才能完成
topic5: 用户缓冲I/O
用户缓冲I/O是在用户空间而不是内核中完成的。标准I/O库(C标准库)或者iostream库(C++标准库)都实现了用户缓冲I/O, 当数据被写入时,会被存储到程序地址空间的缓冲区。当缓冲区数据达到缓冲区大小(buffer size)时,整个缓冲区会通过一次写操作(write调用)全部写出。同样,读操作也是一次读入缓冲区大小且块对其的数据。应用的各种大小不同的读请求不是直接从文件系统读取,而是从缓冲区中一块块读取。通过这种方式,减少系统调用次数,且每次请求的数据大小都是块对齐的,确保I/O操作有很大的性能提升。标准C库中对应的主要API有
FILE* fopen(const char *path, const char *mode); // 打开文件
int fclose(FILE *stream); //关闭流(标准I/O中,打开的文件称为流)
int fgetc(FILE *stream); // 从流中读取一个字节
int fputc(int c, FILE *stream); // 向流中写入单个字节
char* fgets(char *str, int size, FILE *stream); // 从流中读取一行
int fputs(const char *str, FILE *stream); // 向流中写入一行
size_t fread(void *buf, size_t size, size_t nr, FILE *stream); // 读取二进制文件
size_t fwrite(void *buf, size_t size, size_t nr, FILE *stream); // 写入二进制数据
int fseek(FILE *stream, long offset, int whence); // 定位流
int fflush(FILE *stream); // 刷新输出流
需要说明的是
- 调用fflush()时,stream中的的所有未写入内核的数据会被flush到内核中,如果stream是空的,进程中所有打开的流会被flush。 fflush()函数的功能只是把用户缓冲的数据写入到内核缓冲区(内核调用write())。不保证数据最终被写到物理介质上。如果期望写到物理介质上,可以调用fsync()这类函数,即在调用flush()后立即调用fsync(),也就是说,先保证用户缓冲区被写到内核,然后保证内核缓冲区被写到磁盘。
- 标准I/O可以保证单个进程的多个线程可以同时发起标准I/O调用,不会由于并发操作而彼此干扰。标准I/O函数在本质上是线程安全的。在每个函数的内部实现中,都关联了一把锁,一个锁计时器,以及持有该锁并打开一个流的线程。每个线程在执行任何I/O操作请求之前,必须首先获得锁且持有该锁。两个或者多个运行在同一个流上的线程不会交叉执行标准I/O操作。因此在单个函数调用中,标准I/O操作都是原子操作。由于标准I/O函数是线程安全的,各个写请求不会交叉执行导致输出混乱。也就是说,即使两个线程同时发起请求操作,加锁可以保证执行一个写请求后再执行另一个写请求。
标准I/O实现了3种类型的用户缓冲,并为开发者提供了接口,可以控制缓冲区类型和大小
- 无缓冲(Unbuffered): 不执行用户缓冲,数据直接提供给内核,通常很少使用,标准错误默认采用无缓冲
- 行缓冲(Line-buffered): 缓冲是以行为单位执行。每遇到换行符,缓冲区就会被提交到内核。行缓冲对于 把流输出到屏幕时很管用,因为输出到屏幕的消息是通过换行符分割的。因此,行缓冲 是终端的默认缓冲模式,如标准输出。
- 块缓冲(Block-buffered): 缓冲以块为单位执行,每个块是固定的字节数,他很适用于文件处理。默认情况下,和文件相关的所有流都是块缓冲模式。标准I/O称块缓冲为”完全缓冲” 标准I/O库可以通过setvbuf()来修改使用的缓冲模式和缓冲大小。
标准I/O适用于下列情况:
- 可能会发起多个系统调用,希望合并这些调用从而减少开销
- 性能至关重要,希望保证所有的I/O操作都是以块大小执行,从而保证块对其。
topic6: 文件共享
想清楚多进程和多线程对对同一个文件进行操作的行为,需要了解文件I/O的相关数据结构,下面是UNIX系统下打开文件的内核数据结构 ,Linux下类似。
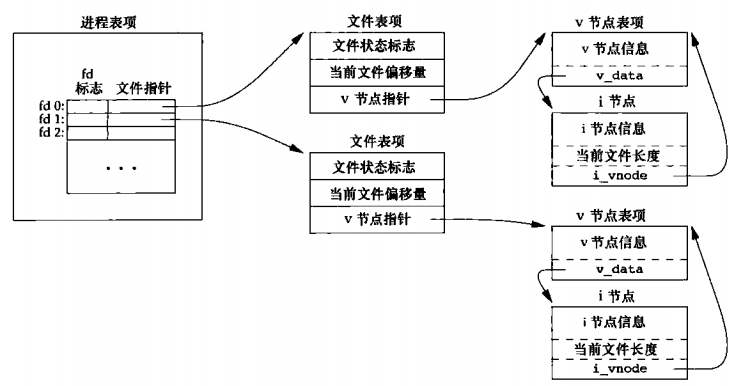
其中:
-
每个进程都维护一份打开的文件描述符表,记录文件描述符以及该文件描述符指向的一个文件表的指针
-
每打开一个文件就对应一张文件表,文件表项包括
-
文件状态标志(读、写、添写、同步等)
-
当前文件偏移量
-
指向该文件v节点表项的指针(Linux下使用了i节点(i-node)结构,包含文件所有者,文件长度,文件在磁盘上位置等)
-
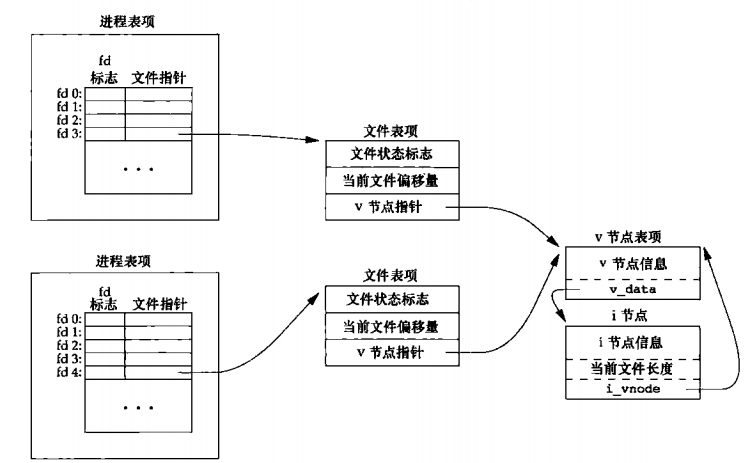
如果两个进程独立各自打开同一个文件,则结构如下:
-
每一次write操作,都从当前文件偏移量开始写入字节,并修改当前文件偏移量(加写入的字节数),如果当前文件偏移量超出了 文件长度大小,则将i节点中当前文件长度设置为当前文件偏移量。
-
如果用O_APPEND标志打开一个文件,则相应的标志被填入到文件表项的文件状态标志中。每次对于这种具有追加写标志的文件执行 写操作时,文件表项中但当前文件偏移量都会被设置为i节点表项中的文件长度。这就使得每次写入的数据都会被追加到当前文件尾端。 若使用lseek定位到文件当前尾端,则文件表项中的当前文件偏移量被设置为i节点中的当前长度,lseek函数只修改文件表项中的当前文件 偏移量,不进行任何I/O操作。
-
多个进程读取同一个文件时都能正常工作,原因是每个进程都有它自己的文件表项,它们各自维护自己的文件偏移量。当多个进程同时 写一个文件时,不能通过执行lseek() + write()来执行,会导致写入被覆盖的情况。而要使用原子操作,比如打开文件时设置O_APPEND标示等。
参考
linux系统编程(第2版)
UNIX环境高级编程(第3版)